최근 한국어 OCR을 사용할 일이 생겼다. OCR 연구가 활발함은 어렴풋이 알고 있었고, 실생활에서도 몇몇 프로그램엔 이미 적용된 기술이니 수월할 거라고 지레 짐작을 했는데…
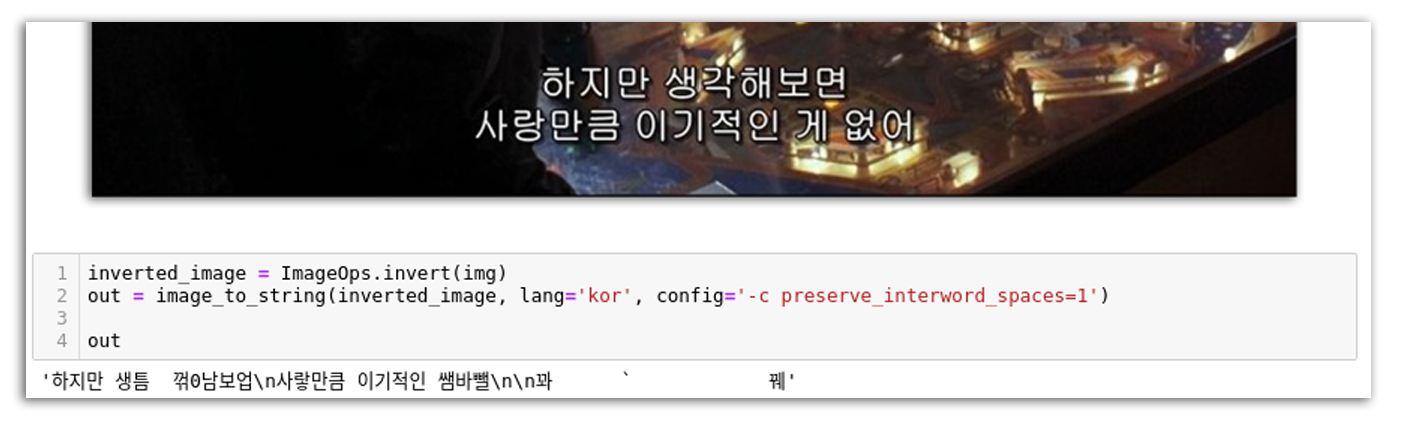
생틈 꺾 사랗만큼 쌤바뺄 와아아오아아유융앙
쉽지 않았기 때문에 꽤나 삽질을 하게 되었고, 결과적으론 NAVER CLOUD PLATFORM 을 활용하는 게 정답이었다. 하지만 네이버 측에서 제공하는 가이드가 (나 같은) 클라우드 입문자에겐 다소 어려웠기에 보충 자료로써 본 글을 작성하고자 한다.
1편에서는 쉽고 빠르게 사용할 수 있는 General OCR을 다루고, 2편에서는 OCR 영역을 지정해 템플릿화해서 사용할 수 있는 Template OCR을 다룰 것이다.
0. 우선 NCP의 회원이 되십시오!

NAVER CLOUD PLATFORM
위 링크에서 해야 할 일은 다음과 같다.
1) 회원가입
2) 상단의 메뉴에서 [서비스] → [Application Service] → [API Gateway]로 이동
3) API Gateway 신청
까지 마치고 나면 아마 좌측에 메뉴가 있는 콘솔 페이지로 이동이 되어 있을 것이다.
좌측의 메뉴에서 [Products & Services] → [AI-Application Service] → [OCR]까지 이동한 후 본격적으로 시작!
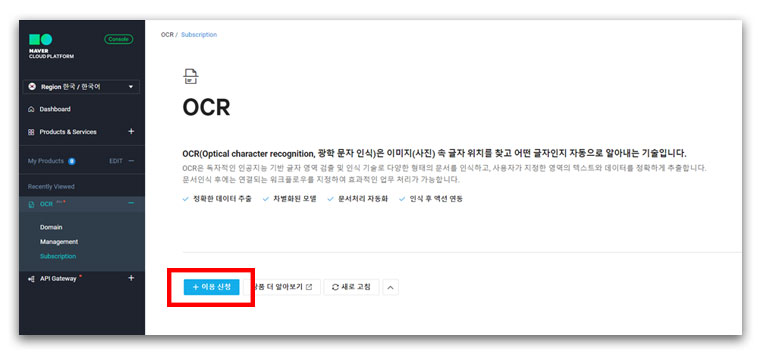
[이용 신청] 클릭!
1. 도메인 생성
위 단계를 성공적으로 마치고 나면 (실패하기엔 너무 간단하지만) 아래와 같이 도메인 생성 창이 나타날 것이다.
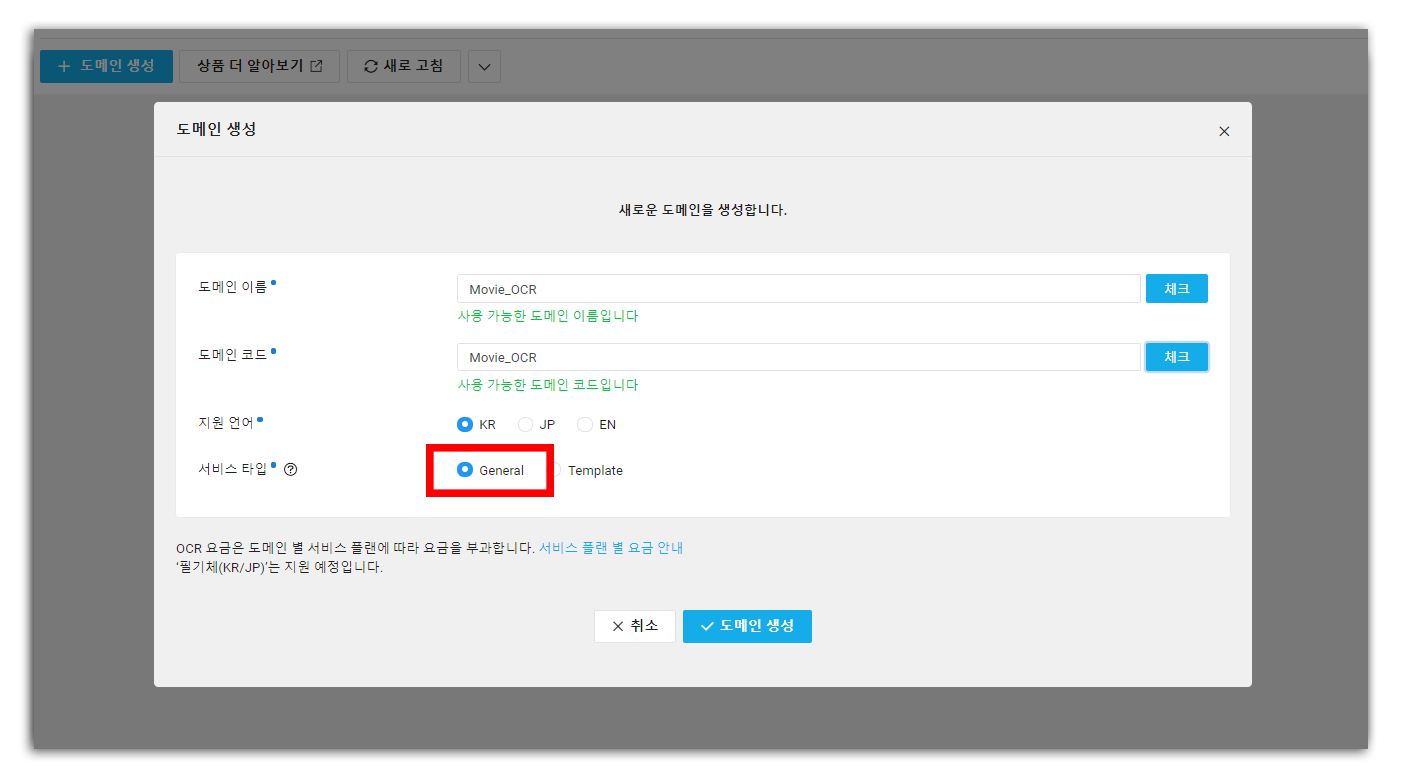
적당한 도메인 명을 입력!
필자는 영화 캡처에서 자막을 긁어오는 OCR API를 만들고자 하므로 도메인 이름을 Movie_OCR이라고 명명했다. 각자 적당한 도메인 이름을 지어 준 후, 1편에서는 General OCR을 다루기로 했으므로 서비스 타입은 General로 체크해준다.
간단히 General과 Template의 차이를 언급하면 다음과 같다.
General: Input 이미지에 포함된 모든 문자를 반환
Template: Input 이미지에서 사용자가 지정한 영역이 포함하는 문자를 반환
혹시 와닿지 않더라도 문제는 없다, 두 타입을 모두 다룰 것이고 실제 데이터를 보면 감이 확 올테니 걱정 말고 다음 스텝으로 진행하자.
2. API 생성
 [Text OCR]을 클릭!
[Text OCR]을 클릭!
생성된 도메인의 동작 컬럼을 보면 Text OCR 버튼이 있다. 이를 누르면 다음과 같은 설정 창을 보게 된다.
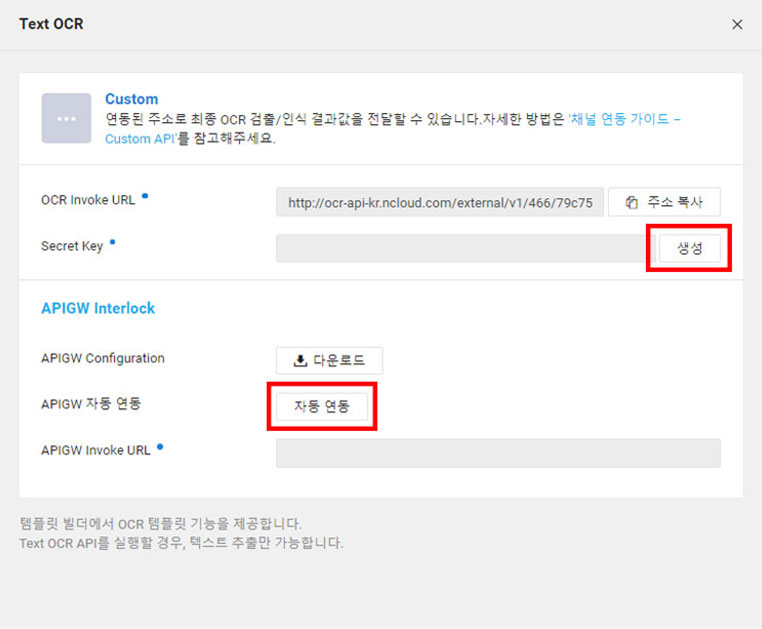 [Text OCR]을 클릭!
[Text OCR]을 클릭!
Secret Key는 보안을 위해 필수로 사용되니 생성. 그리고 NCP는 너무도 편리하게 APIGW(API Gateway) 자동 연동을 지원하니 당장 사용하도록 하자. 클릭!
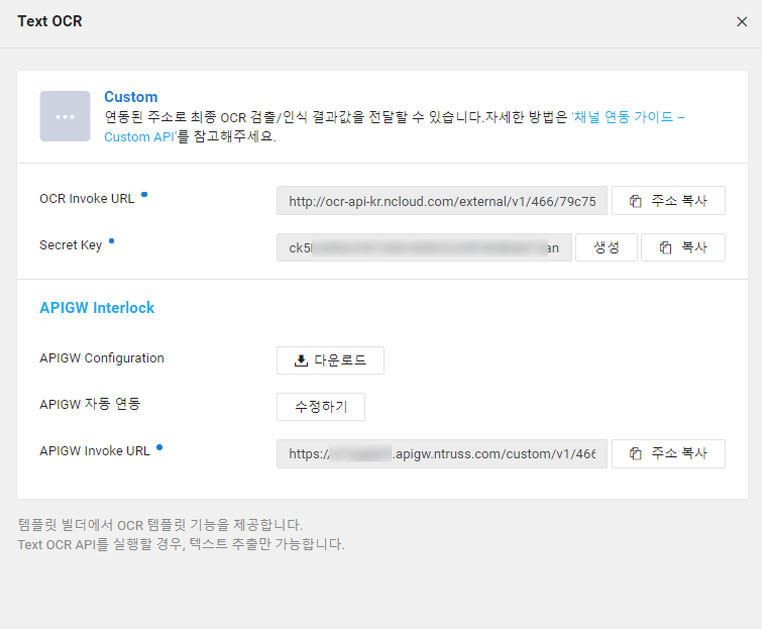 생성된 Secret Key와 APIGW Invoke URL
생성된 Secret Key와 APIGW Invoke URL
Secret Key와 APIGW Invoke URL(OCR Invoke URL이 아님)이 준비되었다면 General OCR을 사용할 준비는 끝이 났다. 네이버에서 제공하는 메인 가이드는 여기까지 적혀있어 “그래서 usage는 어디에…” 하는 마음이 든다. Jupyter Notebook이든 PyCharm이든 본인이 사용하는 파이썬 환경으로 이동하자.
3. API 사용
설명서의 OCR Custom API Spec.을 잘 읽어보면 API가 요구하는 Request의 형태가 적혀 있다.
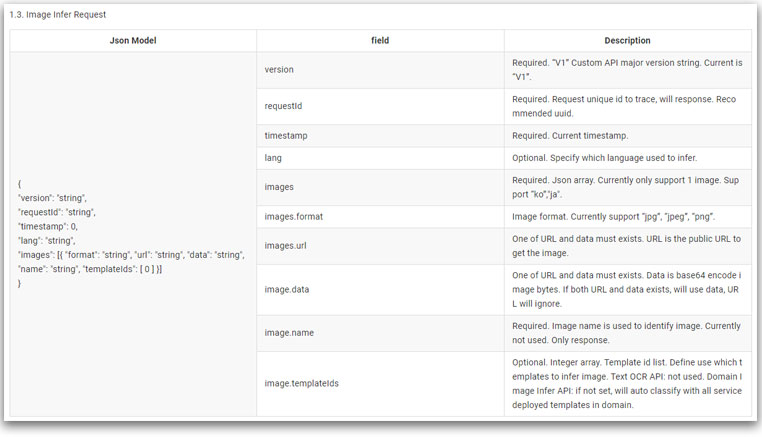
우리에게 중요한 것은 image 필드, 그중에서도 image.data 이다. (나머지는 이름만 봐도 대충 느낌이 온다) Description을 읽어보면 base64로 인코딩된 이미지 바이트를 요구하고 있다.
 예시 이미지 1
예시 이미지 1
영화 캡처에서 자막을 긁어오는 것이 목표이므로, 영화 <비포 선라이즈>의 한 장면을 준비했다. 본 이미지를 우리가 만든 API에게 보내 OCR을 잘 해내는지 확인해보겠다. 기대되는 결과는 “하지만 생각해보면 사랑만큼 이기적인 게 없어”이다.
import json
import base64
import requests
with open("./movie_sample.png", "rb") as f:
img = base64.b64encode(f.read())
# 본인의 APIGW Invoke URL로 치환
URL = "https://<your url>.apigw.ntruss.com/custom/v1/000/<your url>/general"
# 본인의 Secret Key로 치환
KEY = "<your secret key>"
headers = {
"Content-Type": "application/json",
"X-OCR-SECRET": KEY
}
data = {
"version": "V1",
"requestId": "sample_id", # 요청을 구분하기 위한 ID, 사용자가 정의
"timestamp": 0, # 현재 시간값
"images": [
{
"name": "sample_image",
"format": "png",
"data": img.decode('utf-8')
}
]
}
data = json.dumps(data)
response = requests.post(URL, data=data, headers=headers)
res = json.loads(response.text)
output:
{
'version': 'V1',
'requestId': 'sample_id',
'timestamp': 1576660655544,
'images': [{
'uid': '123456a123456b1234567', /*private uid obfuscated*/
'name': 'sample_image',
'inferResult': 'SUCCESS',
'message': 'SUCCESS',
'fields': [
{'inferText': '하지만', 'inferConfidence': 0.99994665},
{'inferText': '생각해보면', 'inferConfidence': 0.99995613},
{'inferText': '사랑만큼', 'inferConfidence': 0.999861},
{'inferText': '이기적인', 'inferConfidence': 0.9999344},
{'inferText': '게', 'inferConfidence': 0.99965876},
{'inferText': '없어', 'inferConfidence': 0.99990153}
],
'validationResult': {'result': 'NO_REQUESTED'}
}]
}
서론의 망한 케이스를 기억한다면 이는 실로 놀라운 정확도다! 다만 문장을 죄다 쪼개놓으니 처리하기가 다소 번거로워 보인다. 아마 이미지 상에 존재하는 모든 글자를 OCR 하기 때문인 것 같은데, 이는 꽤 큰 문제를 야기할 수 있다. 예를 들어 아래와 같은 이미지를 OCR 한다고 생각해보자.
 예시 이미지 2
예시 이미지 2
직관적으로도 자막 뿐만 아니라 “비포 선라이즈” 와 “4월 7일 대개봉” 모두 읽어올 것 같은 느낌이 오는데,
output:
{
'version': 'V1',
'requestId': 'sample_id',
'timestamp': 1576661468349,
'images': [{'uid': '1215abe59a4d454aa9fa1311e749e1c5',
'name': 'Sample',
'inferResult': 'SUCCESS',
'message': 'SUCCESS',
'fields': [
{'inferText': '비포', 'inferConfidence': 0.999838},
{'inferText': '4월', 'inferConfidence': 0.9995884},
{'inferText': '7일', 'inferConfidence': 0.9997598},
{'inferText': '대개봉', 'inferConfidence': 0.99976534},
{'inferText': '선라이즈', 'inferConfidence': 0.9812638},
{'inferText': '오늘', 'inferConfidence': 0.9999317},
{'inferText': '비엔나에', 'inferConfidence': 0.9986216},
{'inferText': '왔는데', 'inferConfidence': 0.9996365},
{'inferText': '재밌게', 'inferConfidence': 0.99931806},
{'inferText': '놀', 'inferConfidence': 0.99954},
{'inferText': '곳을', 'inferConfidence': 0.9995316},
{'inferText': '찾고', 'inferConfidence': 0.9995074},
{'inferText': '있어요', 'inferConfidence': 0.9998353}
],
'validationResult': {'result': 'NO_REQUESTED'}
}]
}
역시나 적중이다. 이 현상을 방지하기 위해선 OCR을 진행할 영역을 지정해주는 것이 필요하다. 그를 위해 Template OCR이 존재한다. 다음 편에서는 Template OCR 사용법에 대해 가이드하도록 하겠다.
한국어 OCR 해내기 (With Naver Cloud Platform) 2편: 입맛대로 커스텀한 OCR 만들기