WMT는 Workshop on Statistical Machine Translation 의 약어로 2006년부터 개최되어 올해로 15회차 (2020.11.19-20) 를 맞이한다. 전통이 깊은 만큼 매년 데이터셋을 업데이트하며 WMT 시리즈를 공개하는데, 이 데이터셋들은 현재 기계 번역의 주축이 되어주고 있다!
다만 논문을 쓰는 입장에서 너무 최신 데이터는 과거 모델의 Baseline 성능 측정을 직접 해야 한다는 부담이 있기 때문에 대체로 WMT2014 - 2016 부근의 데이터를 사용하는 듯하다. 필자도 같은 맥락으로 WMT2016 데이터셋을 활용하고자 했는데… 문제가 발생하여 이를 해결한 과정을 적어보고자 한다.
우선 WMT 2016 공식 홈페이지는 여기를 눌러 방문할 수 있다. 우리는 데이터를 다운로드해 활용하길 원하므로 스크롤을 쭉쭉 내리다 보면 아래와 같은 부분을 만날 수 있다.
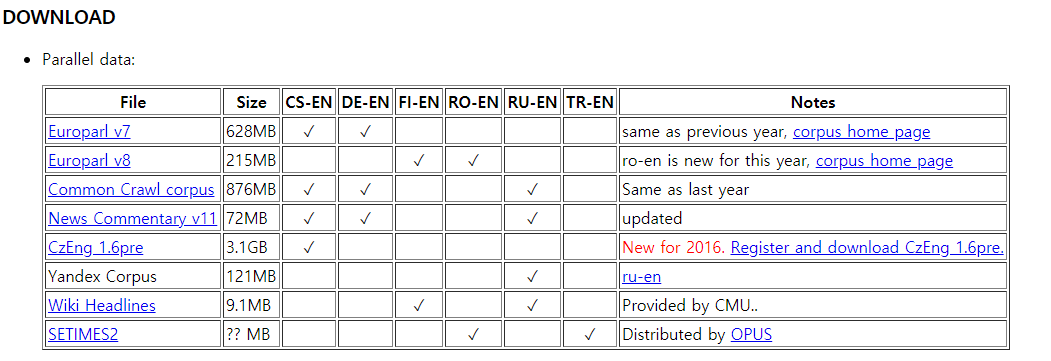
문제가 발생한 것은 바로 News Commentary v11이다. 보기엔 전혀 문제가 없지만 압축을 해제하고 데이터를 직접 살펴보면…
def data_len(path, encoding="utf-8"):
with open(path, "r", encoding=encoding) as f:
dataset = f.read().splitlines()
return len(dataset)
import os
import glob
files = glob.glob("./training-parallel-nc-v11/*")
for file in files:
print(os.path.basename(file), "Length:", data_len(file))
out:
news-commentary-v11.cs-en.cs Length: 191865
news-commentary-v11.cs-en.en Length: 192052
news-commentary-v11.de-en.de Length: 243330
news-commentary-v11.de-en.en Length: 243480
news-commentary-v11.ru-en.en Length: 196844
news-commentary-v11.ru-en.ru Length: 196587
* 혹시 Windows 환경에서 tgz 파일을 다루지 못해 강제 Ubuntu행을 당했다면 7-Zip으로 구원받도록 하자.
분명 병렬 데이터인데 단 한 세트도 병렬이 일치하지 않는다! 어디서부터 병렬 쌍이 틀어진 것인지 알 수 없기 때문에 함부로 데이터를 선별할 수도 없고…
필자는 de-en 데이터가 필요했기에 혹시 길이가 0인 데이터가 포함되어 있나 싶어서 이를 제거해봤는데 제거하고 난 개수는 각각 243068, 241791로 여전히 일치하지 않았다. 사실 길이가 0인 데이터는 완전한 노이즈인데 그것조차 정제되지 않았다는 것에서 “다운로드한 파일이 신뢰할만한가…”에 대해 생각하기 시작했다.
추가로 구분자가 “\n”이 아니라던가… 도 생각해봤지만 이 또한 답이 없는 접근이었다.
의심은 곧 정답을 찾아주었는데, 바로 News Commentary v11를 제작한 CASMACAT 측에서 직접 다운로드하는 것이었다! 문제는 파일이 다소 낯선 xliff 형태라는 것인데, 이를 파싱하는 법을 추가로 정리하고자 한다. 앞서 언급한 것처럼 필자는 de-en 데이터가 필요하기 때문에 de-en 데이터를 예시로 설명하도록 하겠다.
다운로드한 news-commentary-v11.de-en.xliff.gz 파일의 압축을 해제하여 xliff 파일을 얻는다. 얻어진 파일은 아래와 같이 불러올 수 있다.
with open("./news-commentary-v11.de-en.xliff", "r", encoding="utf-8") as f:
raw = f.read()
print("Data Size:", len(raw))
print(raw[:1000])
out:
Data Size: 91850522
<?xml version="1.0" encoding="UTF-8"?>
<xliff version="1.2">
<file source-language="de" target-language="en" original="unknown" datatype="plaintext">
<body>
<trans-unit id="1">
<source>Steigt Gold auf 10.000 Dollar?</source>
<target>$10,000 Gold?</target>
</trans-unit>
<trans-unit id="2">
<source>SAN FRANCISCO – Es war noch nie leicht, ein rationales Gespräch über den Wert von Gold zu führen.</source>
<target>SAN FRANCISCO – It has never been easy to have a rational conversation about the value of gold.</target>
</trans-unit>
<trans-unit id="3">
<source>In letzter Zeit allerdings ist dies schwieriger denn je, ist doch der Goldpreis im letzten Jahrzehnt um über 300 Prozent angestiegen.</source>
<target>Lately, with gold prices up more than 300% over the last decade, it is harder than ever.</target>
</trans-unit>
<trans-unit id="4">
<source>Erst letzten Dezember verfassten meine Kollegen Martin Feldstein und Nouriel Roubini Kommentare, in denen sie mutig die vorherrschende optimistische
소스와 타겟 문장이 제법 예쁘게 나뉘어 있음을 알 수 있다! '\n'을 기준으로 문장을 쪼갠 후, source 태그와 target 태그로 구분하여 저장하면 병렬 쌍을 완성할 수 있다. 다만 유의할 부분은…
src = list()
tgt = list()
for col in raw.splitlines():
if ("<source>" in col) & ("</source>" in col): src.append(col)
if ("<target>" in col) & ("</target>" in col): tgt.append(col)
print(len(src), len(tgt))
out:
239249 239162
위처럼 닫힘 태그를 포함하여 조건식을 설계하면 쌍이 안 맞는다… 확인해보면 닫힘 태그가 누락된 분량이 제법 있다. 기왕 할 때 제대로 검사해서 배포해라 이놈들아ㅠ
따라서 소스 타겟 모두 시작 태그에 대해서만 검사하면 그제서야 올바른 병렬 데이터를 얻어낼 수 있다.
src = list()
tgt = list()
for col in raw.splitlines():
if ("<source>" in col): src.append(col)
if ("<target>" in col): tgt.append(col)
print(len(src), len(tgt))
out:
242770 242770