직접 발표를 진행한 내용입니다,
본 글보다 쉽게 설명하였으니 혹여나 내용이 어렵다면 영상을 먼저 보시길 권장합니다.
Link: my-slide-and-presentation
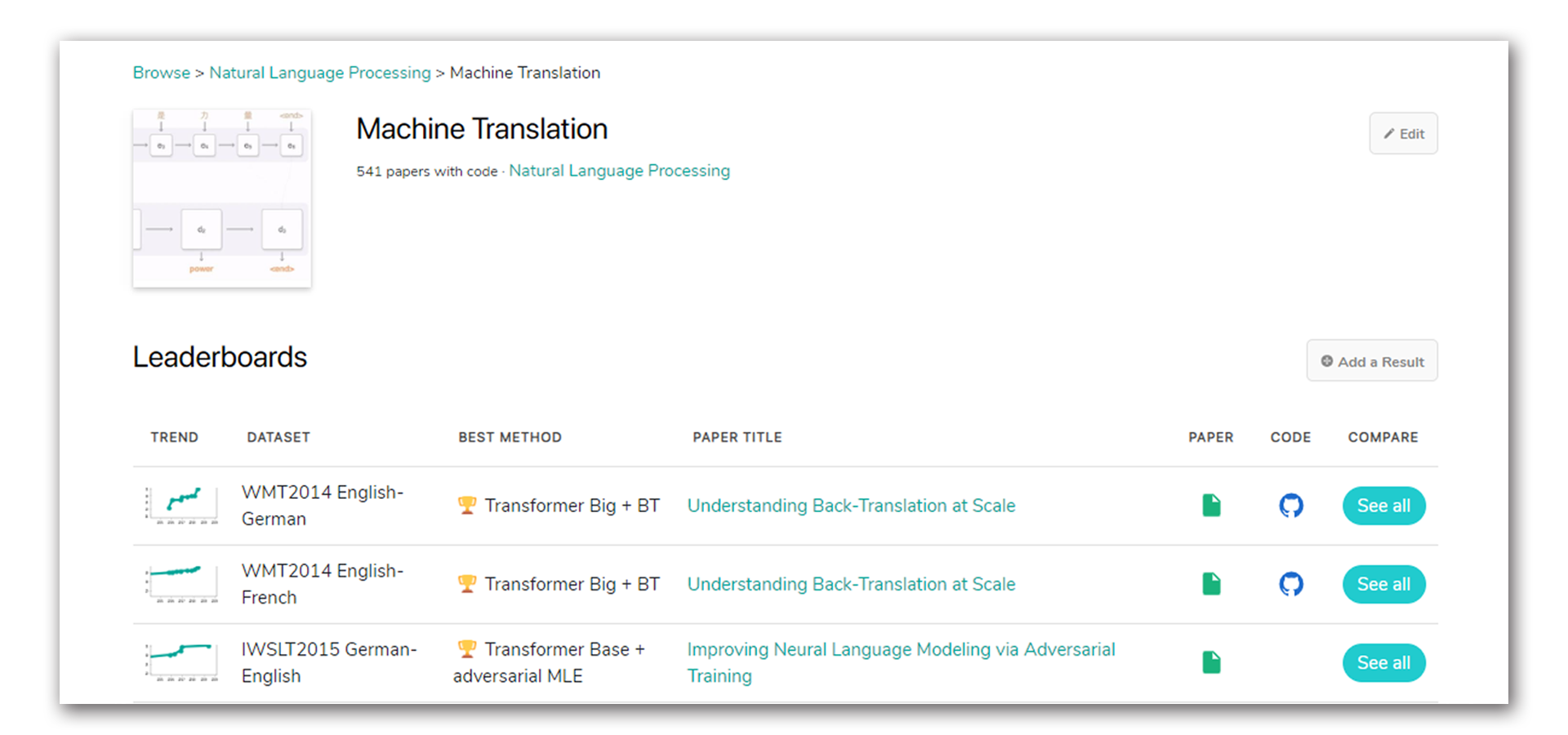
Machine Translation Leaderboards
paperswithcode는 머신러닝의 거의 모든 Task에 대해 오픈된 Dataset을 소개하고 각 Dataset에서 State-of-the-Art를 달성한 방법론을 논문과 소스로 묶어서 소개하는 사이트다. 관심 있는 Task는 종종 확인하며 트렌드를 쫓으면 좋은데, 최근 Machine Translation Task를 확인했다가 처음 보는 개념(Back Translation)이 있어 해당 논문을 읽고 정리를 하고자 한다.
본 글은
<Improving Neural Machine Translation Models with Monolingual Data> 논문과
<Understanding Back-Translation at Scale> 논문을 참고하여 작성되었습니다.
0. Intro
Back Translation이란 개념이 처음 소개된 것은 2016년 ACL에서였다. <Improving Neural Machine Translation Models with Monolingual Data> 논문은 단일 언어 데이터(이하 단일 데이터)로 기계 번역의 유창성을 높이고자 하였다.
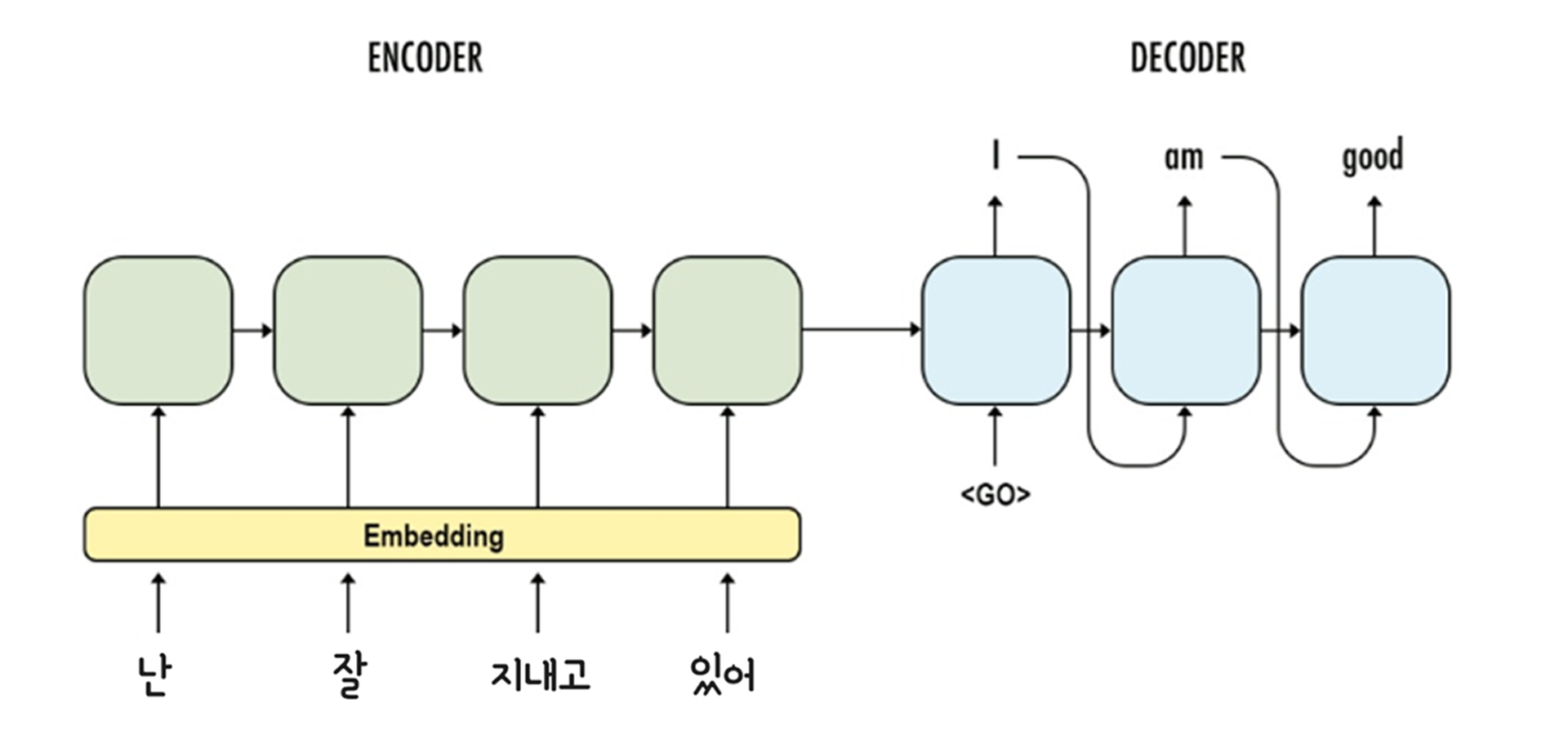
기본적으로 기계 번역 모델은 Encoder-Decoder 구조를 이루며 Source Sentence가 Encoder에 입력되고, Target Sentence가 Decoder에 입력되며 훈련을 진행한다. 고로 두 문장이 한 쌍을 이루는 병렬 데이터가 불가피하다. 그런데 단일 데이터만으로 훈련을 하겠다니? 잘 상상이 가지 않는다. 저자들은 두 가지 방법을 제안했다.
1-1. Dummy Source Sentence
첫 번째 방법은 Encoder의 입력으로 Dummy 값을 주는 것이다. 저자들은 null 토큰을 생성하여 Target Sentence의 단일 데이터와 한 쌍을 이루게끔 하였다. 그리고 Encoder의 모든 Parameter은 Freeze하여 Dummy 값에 대한 학습은 일절 이루어지지 않도록 하였다.
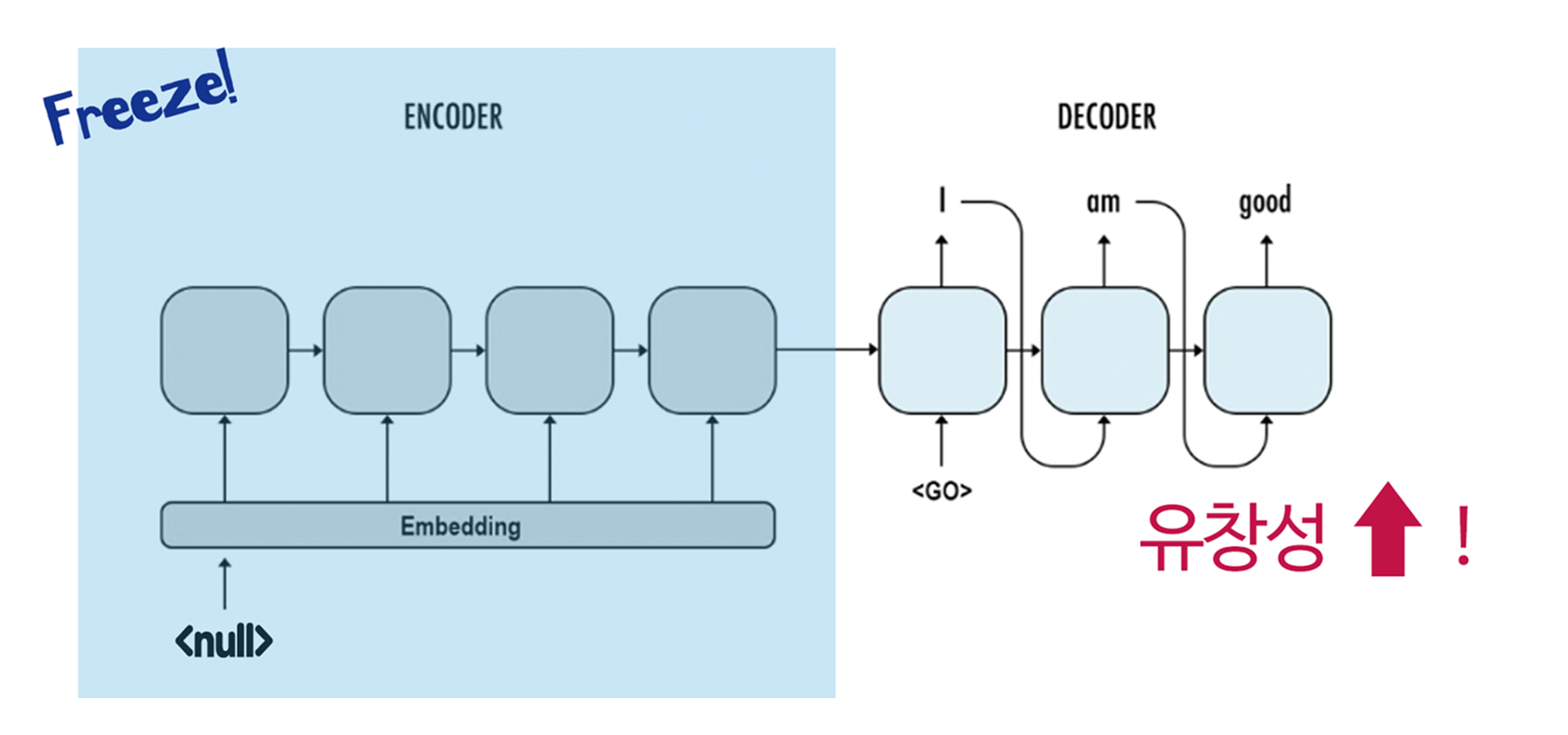
이 경우 Decoder만 새로운 문장에 대해 추가 학습이 진행되는 것과 같은 효과이므로, 저자들이 말한 대로 유창한 번역을 만드는 데에 도움이 될 것 같은 느낌이 든다!
유의할 점은 단일 데이터가 병렬 데이터의 수를 넘어가게 되면 (비율이 1:1을 초과하면) Decoder가 Source Sentence로부터 추출한 정보를 잊어버리고, Target Sentence에 의존적인 양상을 보이게 된다고 한다. 이 문제점을 해결하고자 한 것이 두 번째 방법이고, 바로 Back Translation이다.
1-2. Synthetic Source Sentence (Back Translation)
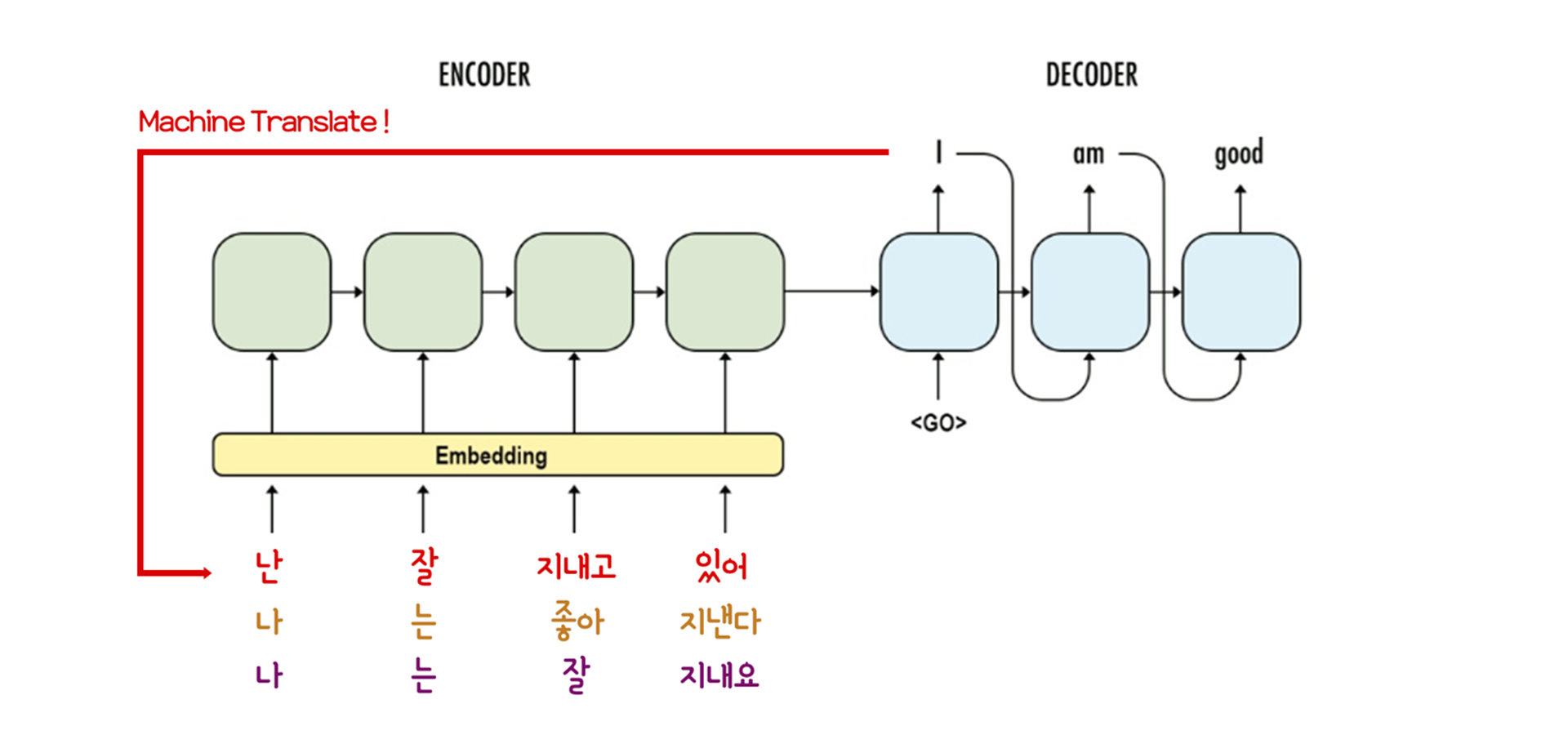
아무런 정보도 담고 있지 않은 null 토큰을 입력으로 주느니, 완벽하지는 않더라도 Target Sentence를 보고 인공적인 Source Sentence를 만드는 방법론이다. 생성된 인공 데이터를 Synthetic Source Sentence라 칭한다. 그리고 인공 데이터를 생성하는 과정을 Back Translation이라 정의하며, 그 과정을 다음과 같이 표현하고 있다.
i.e. an automatic translation of the monolingual target text into the source language.
(즉, 단일 타겟 언어 문장을 소스 언어 문장으로 자동 번역하는 과정이다.)
다수의 독자들은 이 방법이 정말 유용한지에 대해 의심할 것이라 생각한다 (본인이 그랬기 때문에). 하지만 놀랍게도 인공적으로 생성된 데이터가 엉성할수록 성능이 높아진다는 연구 결과가 있다. 이에 대해선 후술하도록 하겠다.
여기까지가 <Improving Neural Machine Translation Models with Monolingual Data> 논문이 제안하는 방법이다. 해당 논문에서도 실험을 진행했지만, 인공 데이터와 실제 데이터의 비율이나 개수 측면에서 다소 경험적으로 보이는 (때려 맞춘) 부분이 있어 여기서 소개하지는 않겠다. 가장 눈에 띄는 결과는 German→English WMT 15 에서 3.6 - 3.7 BLEU를 증가시킨 부분이다 (31.6 BLEU in newstest 2015 with ensemble of 4). 추가로 인공 데이터를 생성하는 방법에 대해서 Greedy Decoding과 Beem Search를 비교한 부분이 있지만, 이 역시 후술할 논문에서 상세하게 다루고 있으니, 어서 다음 파트로 넘어가자.
2. Understanding Back-Translation at Scale
앞서 말했 듯이 Back Translation을 소개한 논문에는 다소 경험적으로 보이는 부분이 있었다. 즉, 분석이 부족했다. 이에 Back Translation을 자세히 분석하려는 시도가 있었고, 해당 논문은 2018년 EMLNP에서 소개되었다. 무려 Facebook과 Google의 합작품인 <Understanding Back-Translation at Scale>이다.
저자들은 무려 6가지의 환경을 가정하고 실험을 진행했다.
1) 인공 데이터 생성 방법 을 먼저 분석하고, 1)에서 최적이었던 결과가 2) 질 좋은 인공 데이터를 생성하는가 에 대해 고찰하였다 (언어적인 측면에서). 또, 인공 데이터를 생성하는 모델도 결국 병렬 데이터로 훈련을 진행해야 하기에 3) 병렬 데이터가 얼마나 있어야 효과적인가? 에 대해 고려했다.
여기서부턴 저자들이 ‘Back Translation의 후속 논문이 안 나오게 하려는구나…’ 하는 생각이 들 정도의 디테일인데, 4) Back Translation을 진행하는 단일 데이터의 도메인이 미치는 영향 과 너무 인공 데이터만 학습하면 산으로 갈 수 있으니 5) 학습 중에 실제 데이터를 학습하는 빈도, 마지막으로 이 모든 걸 종합하여 온 힘 다해 학습했을 때의 성능을 소개하며 논문을 마친다(V100 GPU 128개…).
자, 하나하나 톺아보도록 하자.
1, 2) Synthetic Data Generation Methods & Analysis
앞선 연구에서는 인공 데이터를 생성하는 데에 Greedy Decoding과 Beam Search를 사용했다. 저 두 방법은 모두 MAP(Maximum A-Posteriori)를 사용하며 가장 높은 확률을 갖는 데이터를 생성하게 된다. 저자들은 두 방법 외에 Non-MAP 방법을 비교해보고자 하였다. Non-MAP 방법으론 Random Sampling과 Top-10 Sampling, Noise를 추가한 Beam Search (이하 Noise Beam)이 있다.
각 방법에 대한 간단한 설명과 예문을 첨부한다.

Reference: 원본 문장.
Beam Search: Source Sentence와 Target Sentence의 일부가 주어졌을 때, 다음 단어로 가장 높은 확률의 단어를 즉시 택하는 것을 Greedy Decoding이라 한다. Beam Search는 Greedy Decoding의 발전된 형태로, 두 번째, 세 번째(범위는 Beam Size에 의해 결정)로 높은 확률의 단어도 택해 문장을 ‘만들어 본다’. 그리고 최종적으로 만들어진 문장들의 확률의 총합을 구하여 가장 높은 값을 갖는 문장을 생성한다.
Random Sampling: 모델의 확률 분포에 따라서 랜덤하게 단어를 선택한다. 예를 들어 모델의 확률 분포가 “I”의 다음 단어로 “am”을 90%, “will”을 10%로 가진다면 10문장을 생성했을 때 “I am” 은 9문장, “I will”은 1문장이 나오는 식이다.
Top-10 Sampling: Random Sampling과 유사하지만, 각 단어들을 확률 내림차순으로 정렬했을 때 Top-10을 제외하곤 생성에 포함하지 않는다. 임의성이 Random Sampling보다 덜하므로 보다 문맥에 맞는 문장이 생성된다. 굳이 Top-10인 이유는 5, 20, 50으로 실험을 해봐도 비슷한 결과가 나오기에 그렇다.
Beam + Noise: Beam Search로 생성된 결과에 Noise를 추가하였다. 각 단어를 10%의 확률로 지우고, 10%의 확률로 filler token 인BLANK로 치환하였다.
실험 결과는 다음과 같다.
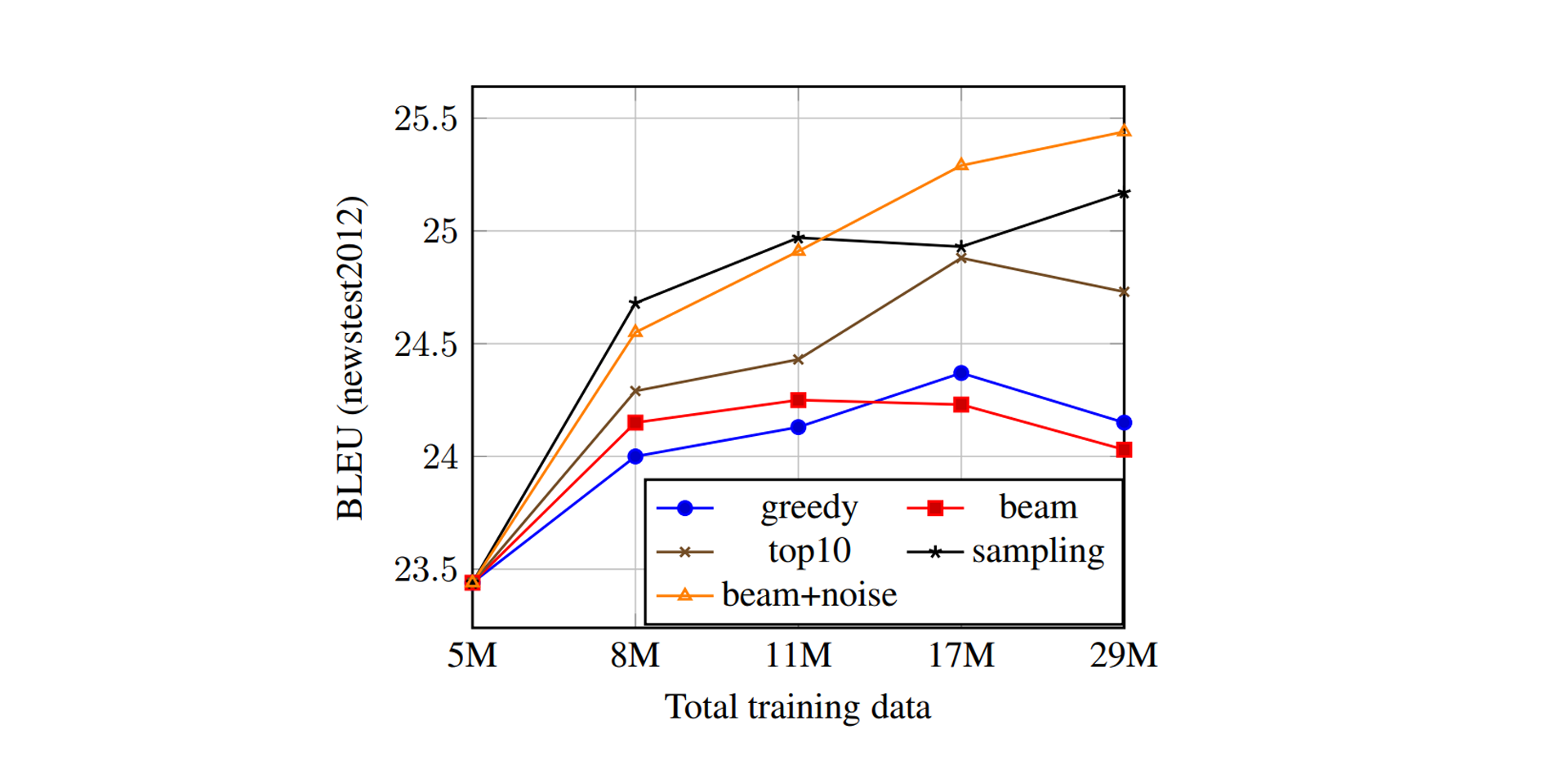
총 500만 개의 병렬 데이터를 학습한 후, 인공 데이터를 수백만 개씩 더하며 2,900만 개까지 실험을 진행한 결과이다. 언어적으로 더 좋은 번역을 만드는 MAP 방법을 Non-MAP 방법이 능가한다는 사실은 다소 놀랍다. 그리고 가장 효과적인 방법 (Noise Beam)은 병렬 데이터만 학습했을 때보다 1.7 - 2.0 BLEU만큼 향상되었다.
저자들은 위 현상이 Beam Search가 너무 그럴듯한 번역을 만들기 때문이라고 말한다. 이를 설명하기 위해 반대로 생각하면, Noise를 더한 Beam Search도 엄연히 MAP 방법인데 가장 좋은 성능을 보였다. 즉 문제는 MAP / Non-MAP가 아니라, 생성된 인공 데이터가 어떤 정보를, 얼마나 포함하느냐가 중요하다는 것이다. (고로 이제부턴 MAP란 단어를 사용하지 않겠다)
쉽게 말하면 번역 모델한테 문제집을 쥐여주는 셈이다. 심화 문제집을 많이 공부한 번역 모델은 그만큼 어려운 문제도 풀 수 있는 능력을 갖출 것이고 (Sampling / Noise Beam), 쉬운 문제집만 풀어온 번역 모델은 현실에서 등장하는 문제조차도 풀기 어렵다는 것이다. 아래는 인공 데이터의 Perplexity 정보이다.
Perplexity: 번역하면 당황도, 혼잡도 정도가 되는데, 번역이 얼마나 개판인지 평가해주는 지표이다. 높을수록 난해한 문장을 생성했다고 이해하면 된다.
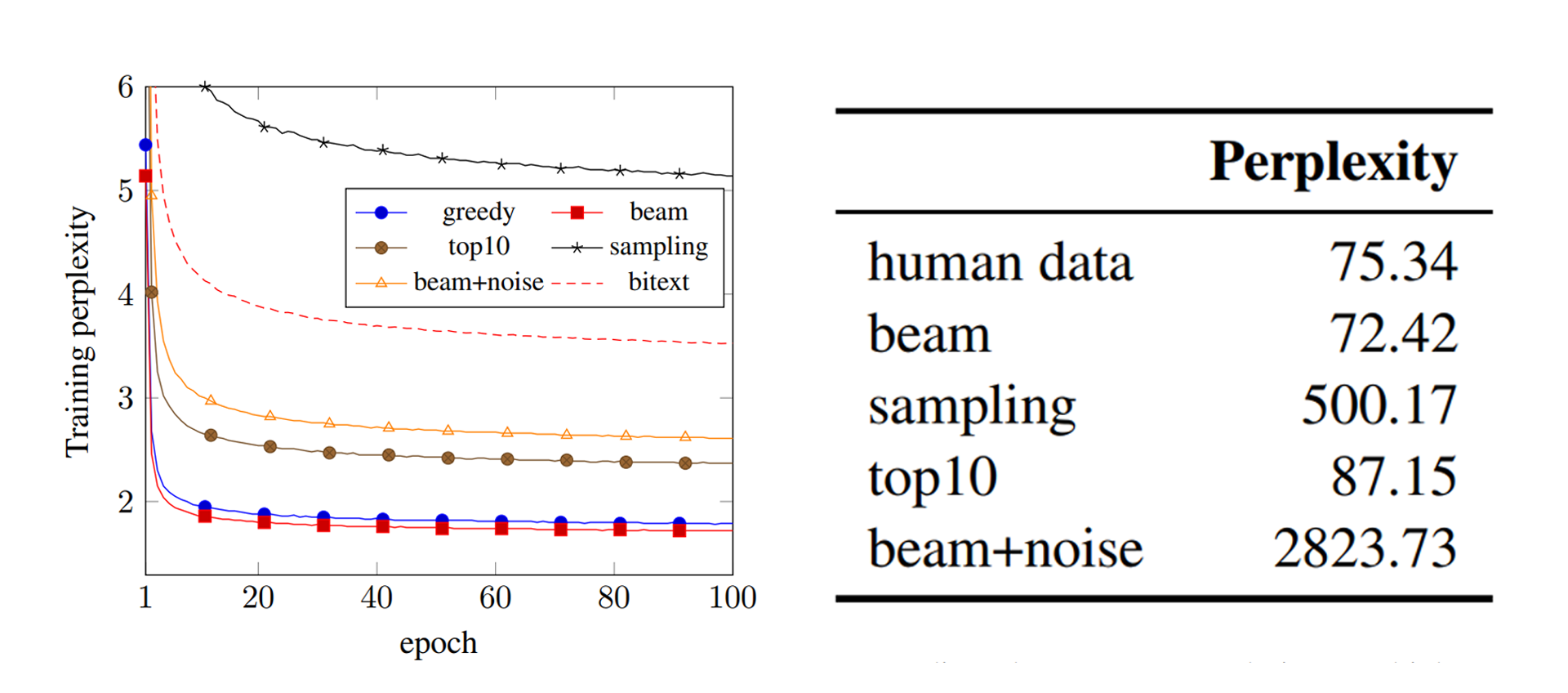
앞서 말한 예시대로라면 Perplexity는 번역 문제집의 난이도라고 표현할 수도 있겠다. 지표로 보니 Sampling과 Noise Beam은 심화 문제집이 확실하다.
다만 저 문제집도 결국 문제 푸는 학생(번역 모델)이 만들었다는 점을 간과할 수 없다. 만약 충분히 학습되지 않은 모델이 어렵게만 인공 데이터를 만든다면, 그건 무작위의 단어를 나열한 것과 크게 다르지 않을 것이다. 따라서 저자들은 Back Translation이 효과적일 수 있는 최소한의 병렬 데이터 수를 알아내야 했다.
3) Low Resource vs. High Resource
앞서 진행한 실험은 500만 개에서 2,900만 개까지의 데이터에서 진행했기 때문에 어쩌면 객관성이 떨어질 수도 있다. 왜냐면 저 정도의 병렬 데이터는 그럴듯한 번역기를 만들기에 충분해서, Random Sampling조차도 이상적인 확률 분포에서 이루어졌을 수 있지 않은가? 그렇기 때문에 저자들은 병렬 데이터 수를 줄여가며 실험을 진행했고, 그 환경을 Low Resource라 칭하였다.
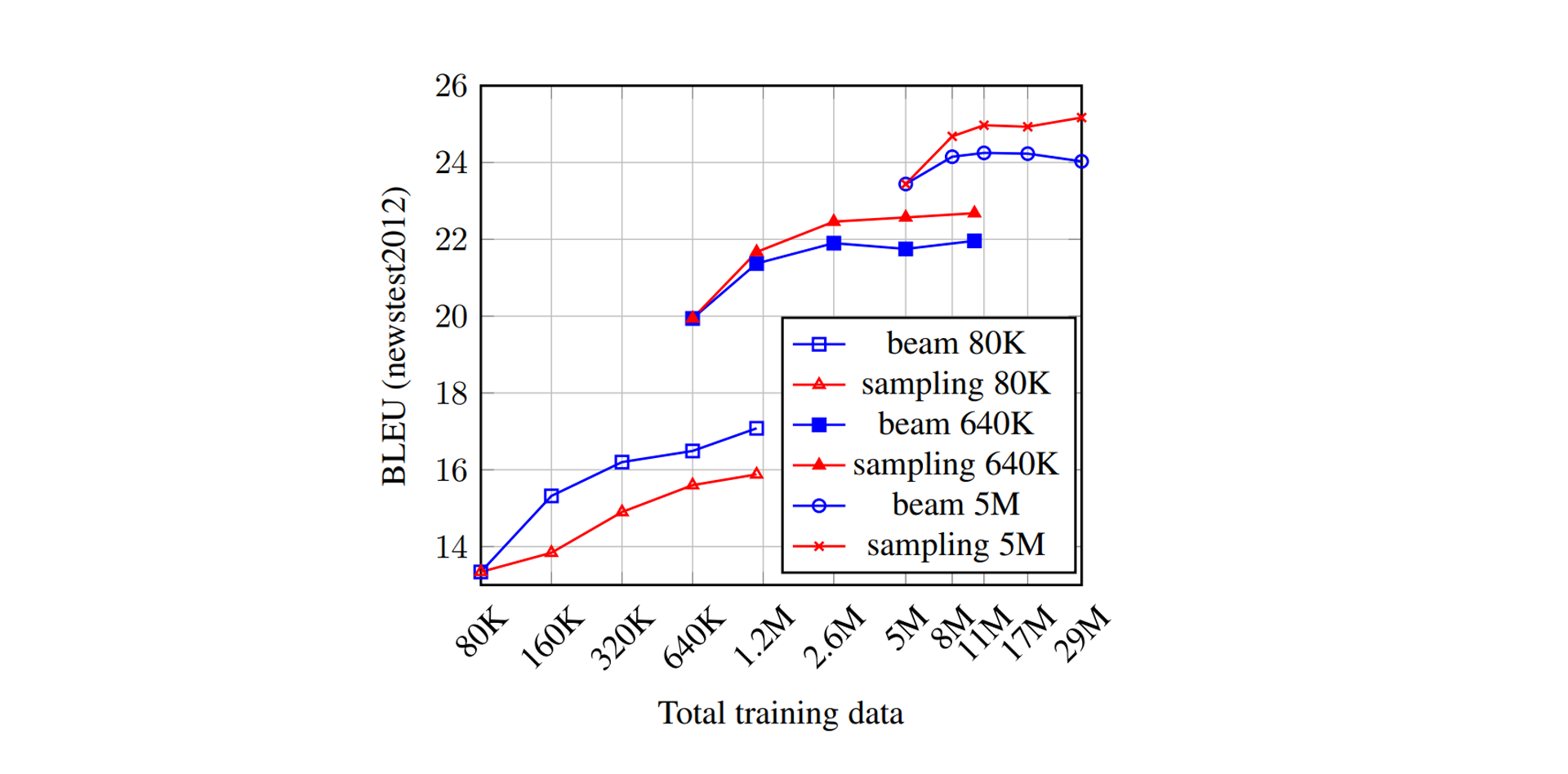
위 그래프는 병렬 데이터를 8만 개까지 줄여가며 실험을 진행한 결과이다. 붉은 선이 Sampling이고, 푸른 선이 Beam. 결과는 한눈에 들어오는 편이다. 적어도 64만 개 이상의 병렬 데이터 를 가지고 있을 때, Sampling이 효과를 보기 시작한다. 추가로, Back Translation 자체는 모든 경우에서 효과적이다. 이쯤에서 우린 번역 모델을 완성하고, 모든 훈련을 마친 후 쓸 수 있는 히든카드를 얻은 셈이다 (중복 할인되는 쿠폰만큼이나 든든하다).
4) Domain of Synthetic Data
Back Translation은 적당한 양의 병렬 데이터만 있으면 활용이 가능하다. 단일 데이터는 모으고자 하면 얼마든지 모을 수 있다. 오픈된 말뭉치 데이터를 써도 좋고, 웹을 크롤링할 수도 있고, 심지어 직접 타이핑을 해도 무방하다. 이때, 단일 데이터의 출처(도메인)와 번역기의 성능은 연관이 있는가? 다시 말해, 소설책으로 학습해도 뉴스에서 쓰일 수 있는가?
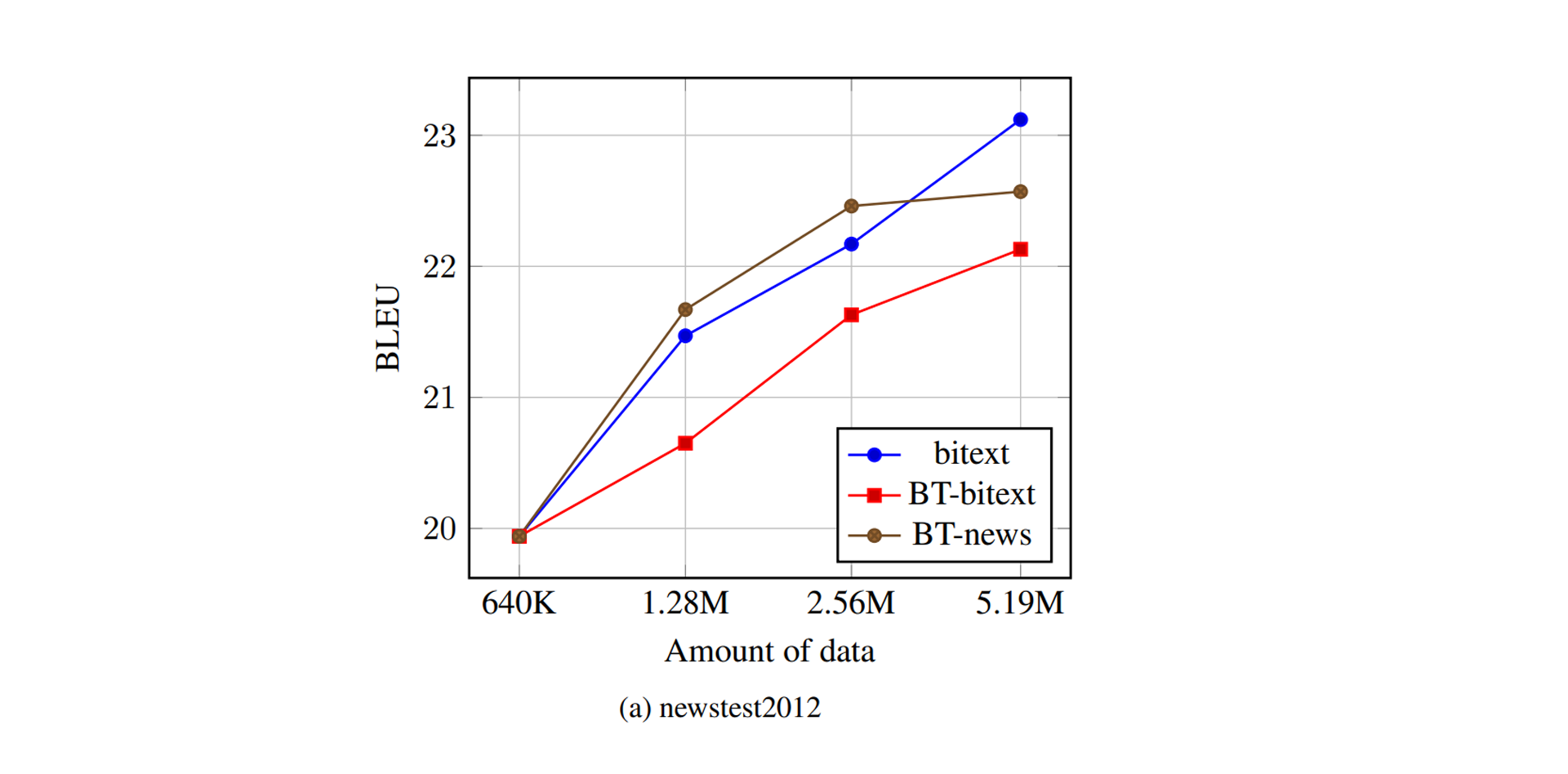
위 그래프는 WMT 의 평가 데이터셋인 newstest 로 실험을 진행한 결과이다. 이름에 명시되어 있듯이 뉴스에서 크롤링한 병렬 데이터이다. 갈색 선이 뉴스 데이터로 Back Translation한 결과, 붉은 선이 일반적인 데이터(정확히는 병렬 데이터의 일부)로 Back Translation한 결과, 푸른 선이 그냥 병렬 데이터로 학습한 결과이다.
특정 구간에서는 Back Translation이 실제 데이터를 능가하기도 한다! 물론 붉은 선은 성능이 떨어지는 걸로 보아 뉴스에 한정적임을 직감할 수 있다. 어느 분야에서나 그렇겠지만 도메인 의존적인 것은 지양해야 한다. 결국 목적은 실제 세상에 적용하고자 함이니, 온실 속 화초는 시들기 마련 아니겠는가? 고로 저자들은 온실 속 화초를 야생에 내놓았다.
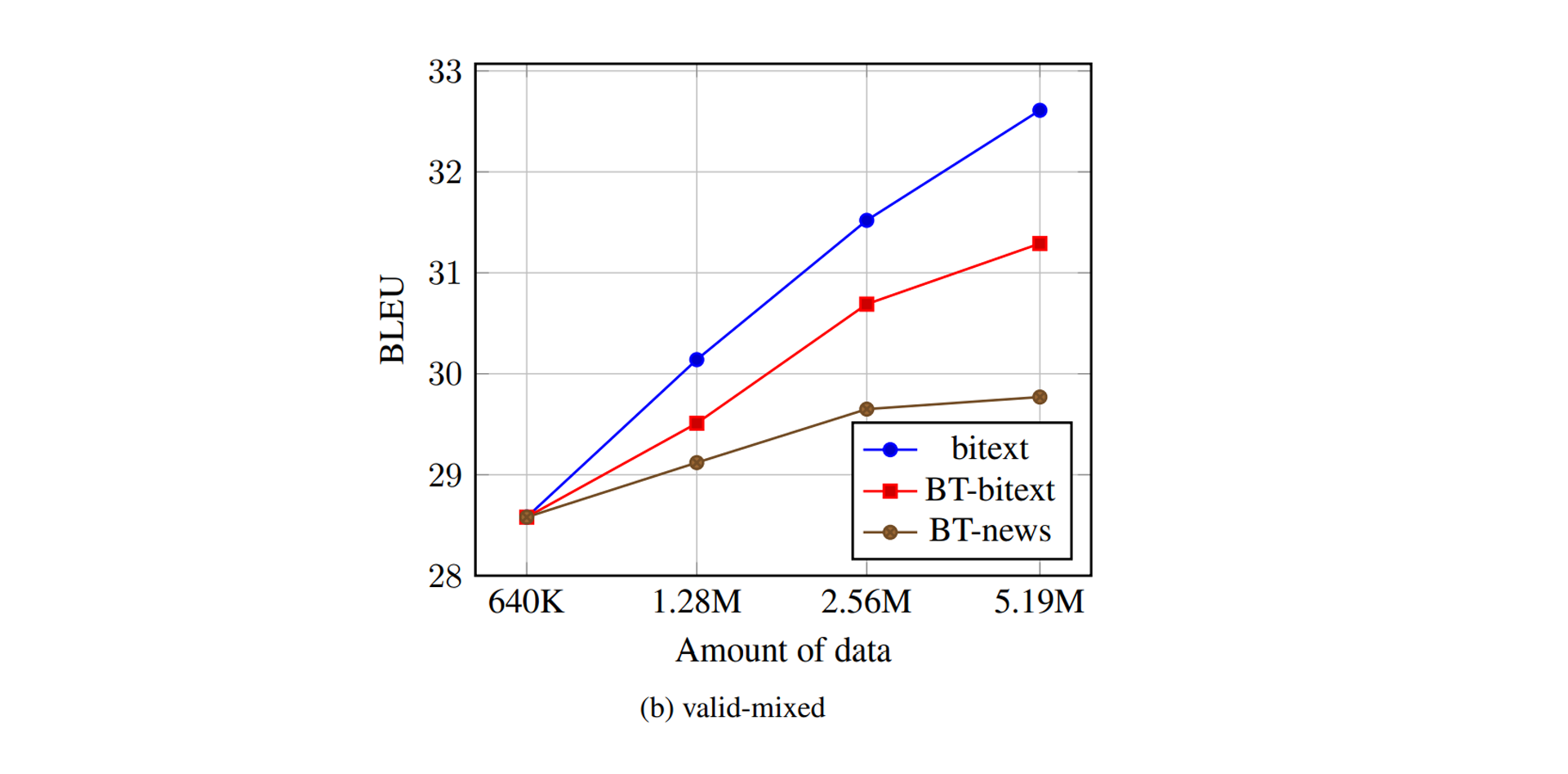
위 그래프는 여러 가지 도메인을 섞은 데이터셋으로 실험을 진행한 결과이다. 뉴스에서 강건했던 갈색 선은 맥 없이 고꾸라지고 말았다. 대신 이 부분에선 첫 실험에서 가려져 있던 빛나는 결과 를 볼 수 있다. 이전 실험도 그렇고 붉은 선이 푸른 선에 비해 성능이 크게 뒤처지지 않는다. 그 말은 곧, 64만 개의 병렬 데이터만 확보된다면 500만 개가 있을 때의 성능을 유사하게 만들어 낼 수 있다는 것이다! 데이터가 적어 중도 포기한 번역 모델이 있다면, 오랜만에 다시 살펴보도록 하자.
5) Upsampling the Bitext
이 부분을 Upsampling이라고 칭한 이유는 잘 모르겠지만(기존에 알던 개념과 연관을 찾기 어렵다), 우선 개념적으론 인공 데이터를 학습하는 도중, 실제 데이터를 방문하는 빈도이다. 앞서 언급한 표현을 빌려오면 Back-Translation은 결국 학생이 직접 만든 문제집을 푸는 셈이기 때문에, 실제 데이터와 동떨어진 내용을 학습하게 될 우려가 있다. 따라서 실제 데이터를 방문하는 빈도에 대한 실험은 의의를 가진다.
실제로 저자들은 방문(visit)이란 표현을 사용했다.
Upsampling Rate가 1이면 인공 데이터를 1번 볼 때 실제 데이터도 1번 보는 것(1:1)이고, 8이면 인공 데이터를 1번 볼 때 실제 데이터를 8번 보는 것(1:8)이다. 즉, Upsampling Rate가 높을수록 실제 데이터를 많이 학습하게 된다.
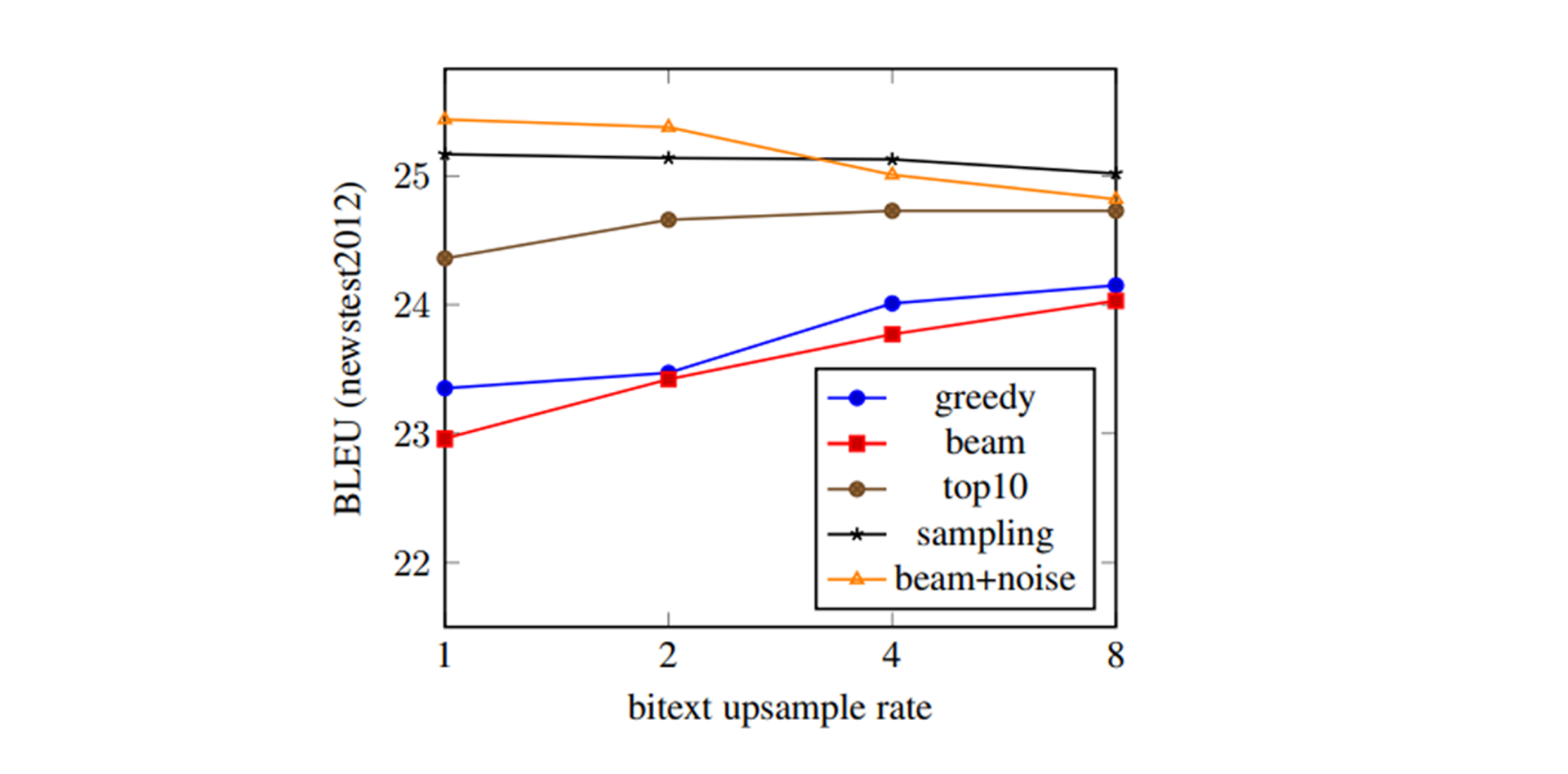
Greedy Decoding과 Beam Search는 Upsampling Rate가 높아질수록 성능이 올라가는 모습을 보인다. 반면에 Top-10 Sampling, Random Sampling, Noise Beam은 성능에 큰 변화가 없거나 심지어 떨어지는 모습을 보인다.
단순하게 Greedy Decoding과 Beam Search가 만드는 문제집이 너무 쉽기 때문이라고 생각할 수 있다. 반대로 나머지 방법론이 만든 문제집은 충분히 좋은 내용이 담긴 심화 문제집이었기에, 굳이 실제 데이터를 보지 않아도 성능이 잘 나오는 것이다.
마치며
실험 결과는 서론에 언급했듯이 WMT 2014 에서 35.0 BLEU로 State-of-the-Art 성능을 달성하였다. 자세한 실험 환경과 결과값이 궁금하다면 논문을 참고하길 바란다.
본 논문은 기계 번역에 포커스를 맞춘 논문이지만, 어렴풋한 느낌으로는 많은 분야에 활용이 가능할 것 같다. 인공 데이터가 의미 있으며 실제 데이터를 능가할 수도 있다는 것을 증명하였으니, 모두 각자 연구하는 분야에 적용시킬 궁리를 해보도록 하자!