이전 글
- 한국어 OCR 해내기 1편: 가뿐하게 OCR API를 만들고 쓰기
- 한국어 OCR 해내기 2편: 입맛대로 커스텀한 OCR 만들기
- 음성인식 코드 짜는 최단 경로: 순식간에 STT 완성하기
- 텍스트를 음성 mp3로 간단하게 변환하기: 딥러닝 몰라도 TTS 하는 법
자연어 처리를 공부하는 사람 중 코딩을 즐기는 편이라면 아마 본인이 직접 제작한 번역기가 있을 것이다. 대다수의 딥러닝 분야들이 그러하듯이 모델의 구조도 중요하지만 그보다 데이터의 양이 절대적으로 성능에 직결된다(물론 RNN과 Transformer를 비교하자는 건 아니다).
그런 의미에서 Back Translation 이라는 개념은 데이터를 왕창 생산(뻠삥)할 수 있다는 점에서 굉장히 매력적인 전략이었다(자세한 내용이 궁금하다면 Back Translation 정리 를 참고하자). 하지만 그마저도 64만 개 이상의 병렬 데이터가 있을 때부터 효과를 보인다는 것에서 토이 프로젝트에 적용하기는 쉽지 않았다.
그런 와중에 Naver Cloud Platform(이하 NCP)의 Papago NMT 를 발견했는데, “구글 번역기 복붙해서 쓰지 누가 이걸 이렇게 쓰나…?” 라는 생각을 하다가 “파파고는 그래도 64만개는 넘게 학습하지 않았을까…?” “Back Translation과 결합하면 어떨까?!” 하는 아이디어가 번뜩 떠오른 것이다! 이른바 <네이버의 기술력으로 내 번역기 버프하기> 프로젝트!
1. 애플리케이션 등록
언제나와 같이 NCP로 이동하여 서비스를 신청하도록 하자. [서비스] → [AI Service] → [Papago NMT]로 이동한 후 [이용 신청하기]를 눌러주길 바란다.

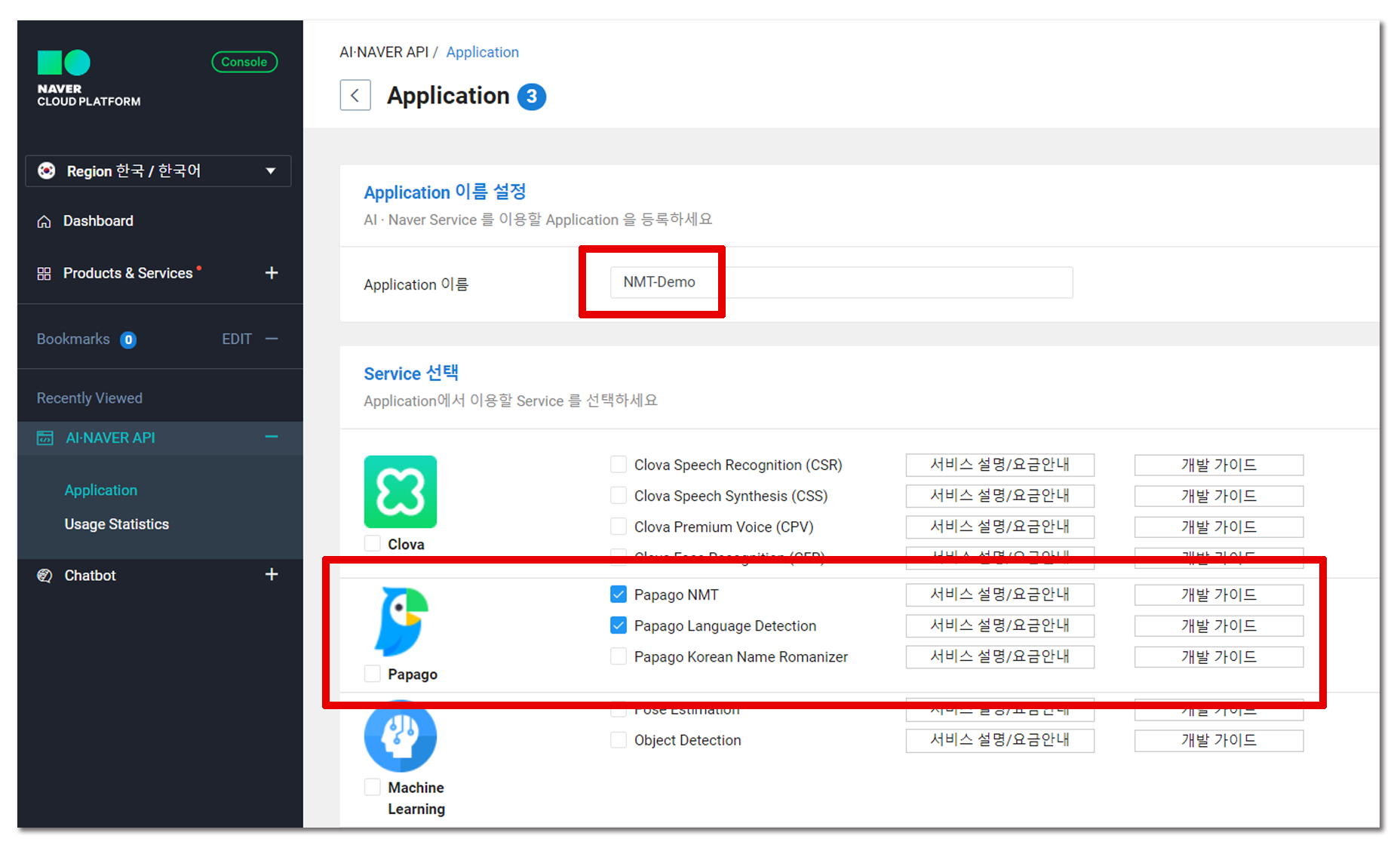
그리고 사용할 서비스로 Papago NMT와 Papago Language Detection 을 체크한다. Papago Language Detection 도 유료로 책정이 되기 때문에 번역할 언어를 매번 지정해줘도 상관 없다면(사실 데이터 구축에 사용할 예정이니 이게 맞다) 체크를 하지 않아도 된다. 필자는 크레딧에 아직 여유가 있기에 최대한 많은 것을 사용해보도록 하겠다!
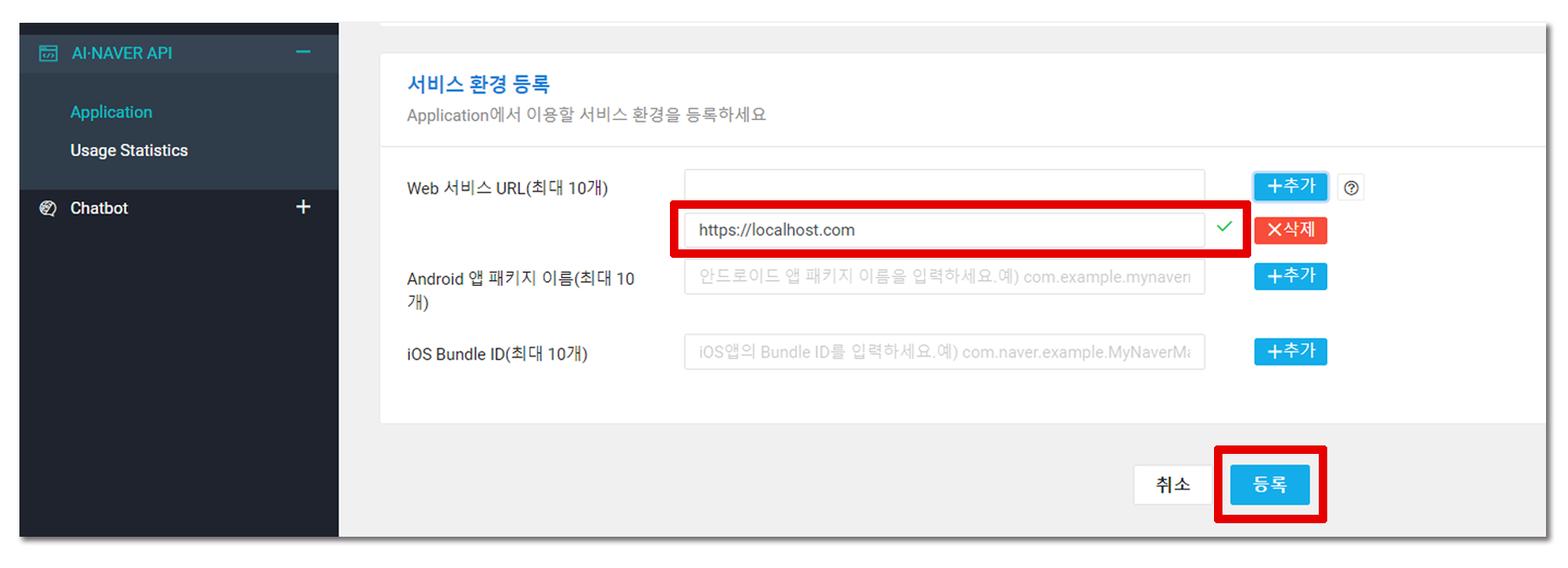
로컬 환경에서만 작동할 예정이므로 서비스 환경 등록 부분에는 https://localhost.com 를 입력하고 추가하면 애플리케이션을 등록할 수 있다.
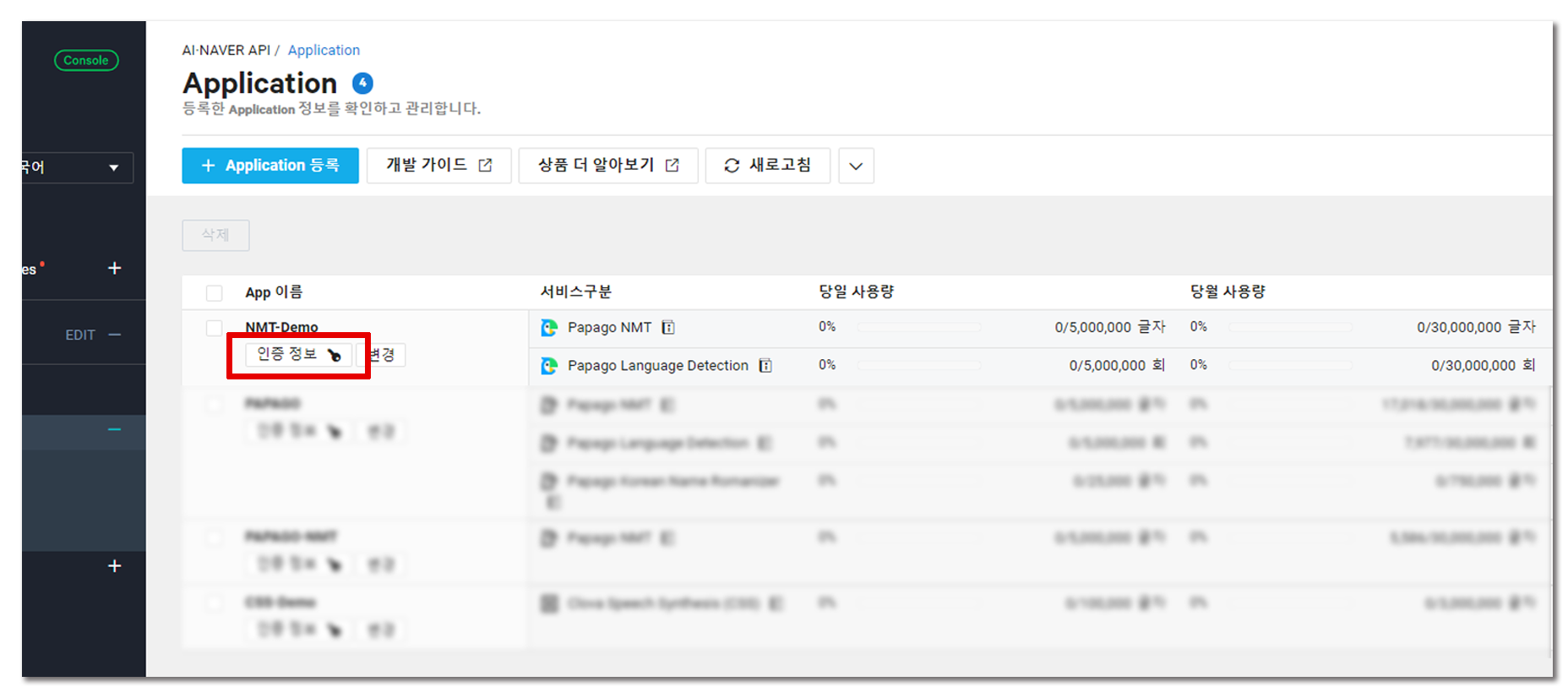
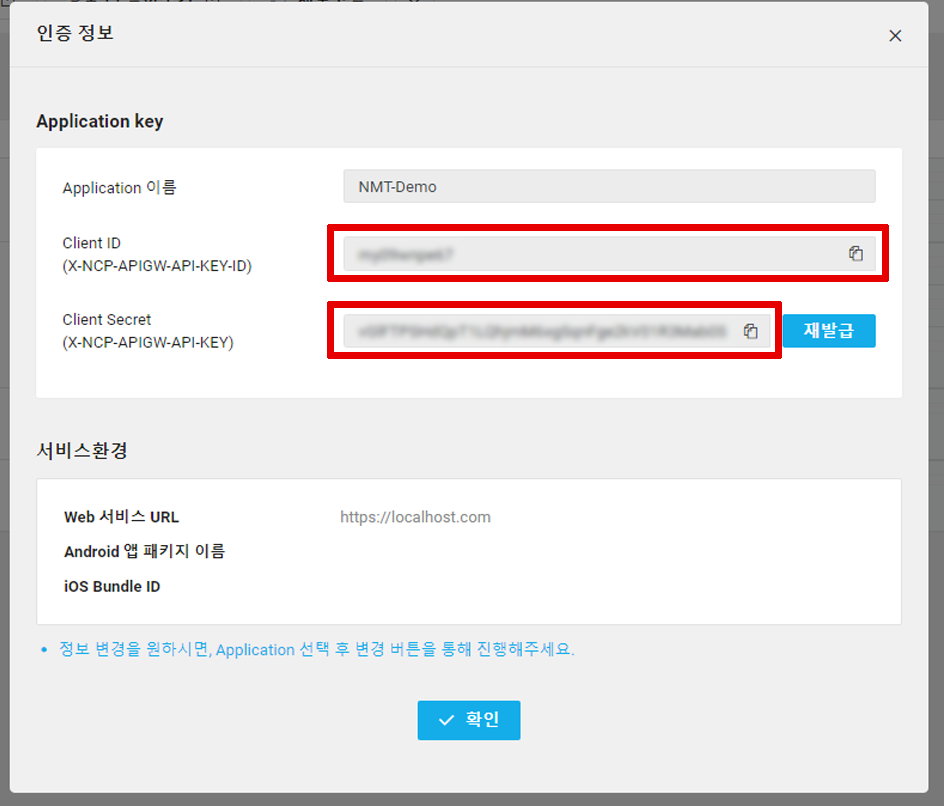
등록을 완료한 후, 인증 정보를 눌러 Client ID와 Client Secret을 메모해두면 NCP에서 할일은 끝!
2. API 사용
NCP측에서 제공하는 API 참조서에 따르면 요청에 포함되어야 할 정보는 다음과 같다.

필자는 위 파라미터 중 source를 Papago Language Detection를 사용해서 알아내고자 한다. 해당 기능을 아래와 같이 함수로 정의했다.
import os
import sys
import urllib.request
import json
def get_language_code(client_id, client_secret, text):
""" Language Code
ko : 한국어
en : 영어
ja : 일본어
zh-CN : 중국어 간체
zh-TW : 중국어 번체
vi : 베트남어
id : 인도네시아어
th : 태국어
de : 독일어
ru : 러시아어
es : 스페인어
it : 이탈리아어
fr : 프랑스어
"""
query = "query=" + urllib.parse.quote(text)
url = "https://naveropenapi.apigw.ntruss.com/langs/v1/dect"
request = urllib.request.Request(url)
request.add_header("X-NCP-APIGW-API-KEY-ID", client_id)
request.add_header("X-NCP-APIGW-API-KEY", client_secret)
response = urllib.request.urlopen(request, data=query.encode("utf-8"))
rescode = response.getcode()
if rescode==200:
response_body = json.loads(response.read())
lang_code = response_body["langCode"]
return lang_code
else:
raise Exception("Error Code:", rescode)
번역하고자 하는 문장을 전달하면 해당 문장의 언어를 코드로 반환하는 함수이다. 서론에 언급한 Back Translation은 각자의 번역기가 학습한 병렬 말뭉치에 대한 번역만 진행하면 되므로 ko 또는 en 등으로 직접 정의해줘도 좋다.
아래는 본격적인 번역 함수로 문장과 시작 언어, 도착 언어를 전달하면 된다. 추가적으로 honorific라는 녀석이 있는데, 영한번역 시 사용할 수 있는 높임말을 제공해주는 옵션이다.
def get_translation(client_id, client_secret, text, _from, to, honorific=False):
data =\
"source=" + _from + \
"&target=" + to + \
"&text=" + urllib.parse.quote(text)
if honorific & (_from=="en"): data += "&honorific=true"
url = "https://naveropenapi.apigw.ntruss.com/nmt/v1/translation"
request = urllib.request.Request(url)
request.add_header("X-NCP-APIGW-API-KEY-ID",client_id)
request.add_header("X-NCP-APIGW-API-KEY",client_secret)
response = urllib.request.urlopen(request, data=data.encode("utf-8"))
rescode = response.getcode()
if(rescode==200):
response_body = json.loads(response.read())
translated = response_body["message"]["result"]["translatedText"]
return translated
else:
raise Exception("Error Code:", rescode)
위 두 함수를 종합하여 번역을 해보자!
text = \
"""
이번 모듈은 JSON 형태로 사용하는 방법을 알아내지 못했다. (필자의 견문이 부족해서…)
하지만 Usage만 잘 살펴도 원하는 대로 커스텀 할 수 있을 정도로 코드가 간단하니, 걱정은 말자!
아래 소스를 실행하면 text의 텍스트가 음성 파일로 변환되어 소스 경로에 저장된다.
참고: 필자는 Jupyter Notebook에서 테스트를 진행했으며 그 외의 환경에서는 동작하지 않을 수 있다.
"""
client_id = "<YOUR_CLIENT_ID>"
client_secret = "<YOUR_CLIENT_SECRET>"
target_code = "en"
code = get_language_code(client_id, client_secret, text)
print("원본 문장:" + text)
ko2en = get_translation(client_id, client_secret, text, code, target_code)
print("한영 번역 결과:\n" + ko2en + "\n")
원본 문장:
이번 모듈은 JSON 형태로 사용하는 방법을 알아내지 못했다. (필자의 견문이 부족해서…)
하지만 Usage만 잘 살펴도 원하는 대로 커스텀 할 수 있을 정도로 코드가 간단하니, 걱정은 말자!
아래 소스를 실행하면 text의 텍스트가 음성 파일로 변환되어 소스 경로에 저장된다.
참고: 필자는 Jupyter Notebook에서 테스트를 진행했으며 그 외의 환경에서는 동작하지 않을 수 있다.
한영 번역 결과:
The module did not figure out how to use it in the form of JSON. (Lack of my knowledge...))
But the code is simple enough to customize just by looking at Usage, so don't worry!
When you run the source below, the text in the text is converted to a voice file and stored in the source path.
Note: I have conducted the test on the Jupiter Notebook and may not work in any other environment.
번역 결과야 의심할 여지 없이 좋다! 이를 활용해 인공 말뭉치를 구축하여 번역기를 발전시킬 수 있겠다. 다만 본인의 데이터 크기를 고려하여 과금이 얼마나 진행될지 계산 후 진행하도록 하자…! 실제로 성능의 향상이 (있을거라 기대되지만) 있는지는 필자가 직접 테스트해 본 후 이 포스팅에 결과를 업데이트하도록 하겠다 (당장은 기약이 없다ㅠ).
추가로 “만약 파파고 모델로 Back Translation을 진행한다면 어떨까?”라는 의문이 생겨 한영한 번역 결과를 덧붙인다. 높임말 옵션을 사용하면 어떻게 되는지도!
한영 번역 결과:
The module did not figure out how to use it in the form of JSON. (Lack of my knowledge...))
But the code is simple enough to customize just by looking at Usage, so don't worry!
When you run the source below, the text in the text is converted to a voice file and stored in the source path.
Note: I have conducted the test on the Jupiter Notebook and may not work in any other environment.
한영한 번역 결과:
모듈에서는 JSON의 형태로 사용하는 방법을 파악하지 못했다.(내가 아는 지식이 부족해서...)
하지만 사용법만 보고 커스터마이징할 수 있을 정도로 코드가 간단하니 걱정하지 마십시오!
아래 소스를 실행하면 텍스트의 텍스트가 음성 파일로 변환되어 원본 경로에 저장된다.
참고: 나는 목성 노트북에서 테스트를 실시했으며 다른 환경에서는 작동하지 않을 수 있다.
한영한 번역 결과(높임말):
모듈에서 JSON의 형태로 사용하는 방법을 파악하지 못했습니다. (지식이 부족합니다...)
하지만 이 코드는 사용법만 보고도 사용자 지정할 수 있을 정도로 간단하니 걱정하지 마세요!
아래 소스를 실행하면 텍스트의 텍스트가 음성 파일로 변환되어 원본 경로에 저장됩니다.
참고: 저는 목성 노트북에서 테스트를 수행했고 다른 환경에서는 작동하지 않을 수 있습니다.
한영한 번역을 잘 만들어낸다는 것은 문장의 핵심을 번역에 잘 반영하고 있다고 해석할 수 있다. 게다가 높임말 옵션은 적용되지 않은 결과랑 비교해서보니 뭔가 귀엽게도 보인다, 갑자기 순해진 느낌이랄까?
항상 같은 결과를 보여주는 걸 보니 Beam Search 기반으로 번역을 생성하는 듯 하다 (안정성을 생각하면 당연하다). 논문을 따르면 문장이 난해할 수록 높은 성능을 보이던데… 성능이 너무 좋아 문제가 되려나 싶다… 이상!