이전 글
1편에서 쉽고 빠르게 OCR API를 만들어서 사용했지만 원치 않는 부분에 대해서도 OCR이 진행되어 결과에 노이즈가 발생하는 문제가 있었다. 2편에서는 이 문제를 해결할 수 있는 Template OCR에 대해 다룰 것이다.
모든 설명은 1편을 선행했다고 가정하니, 혹시라도 건너뛰었다면 위 링크로 이동해 0. 우선 NCP의 회원이 되십시오! 부분까지는 따라 하고 오길 권장한다.
1. 도메인 생성
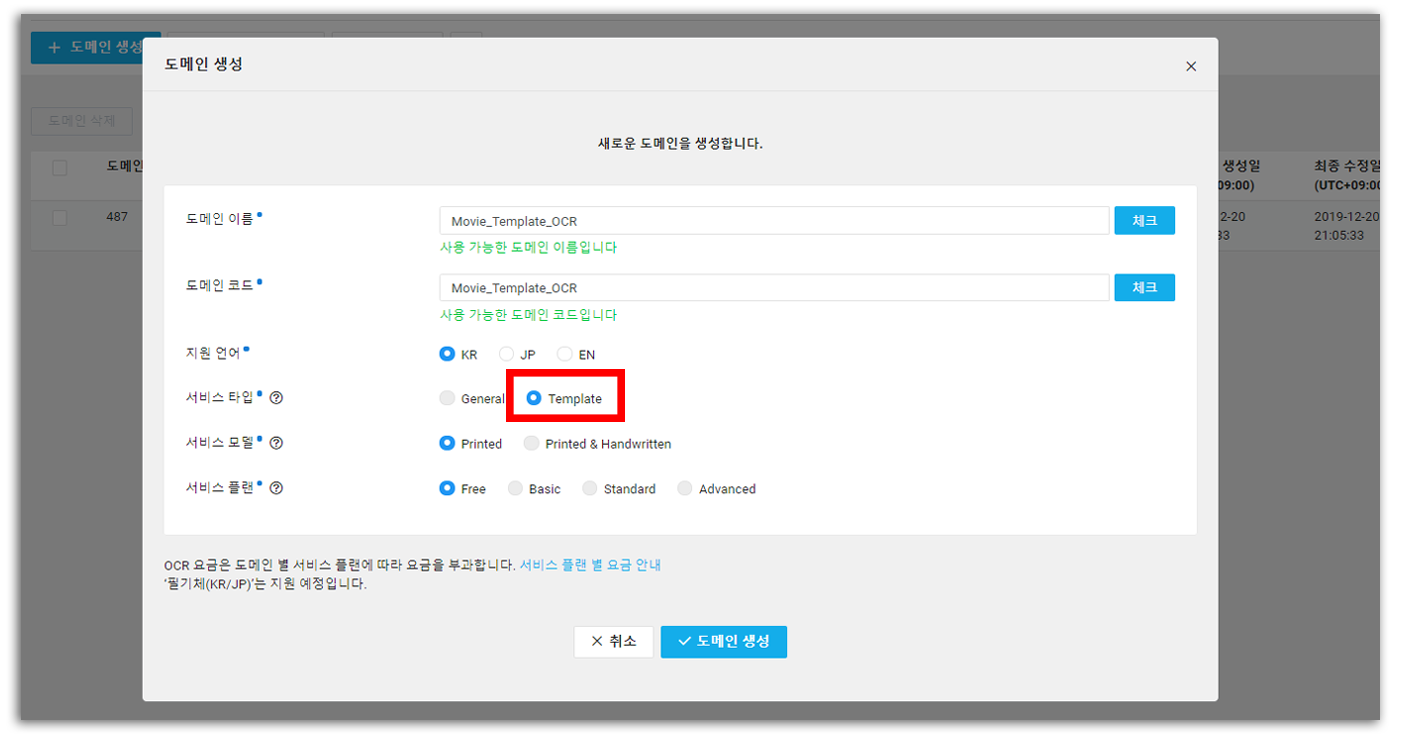 Template 도메인 생성
Template 도메인 생성
General OCR을 만들 때와 동일하게 도메인을 먼저 생성한다. 서비스 타입은 Template로 선택!
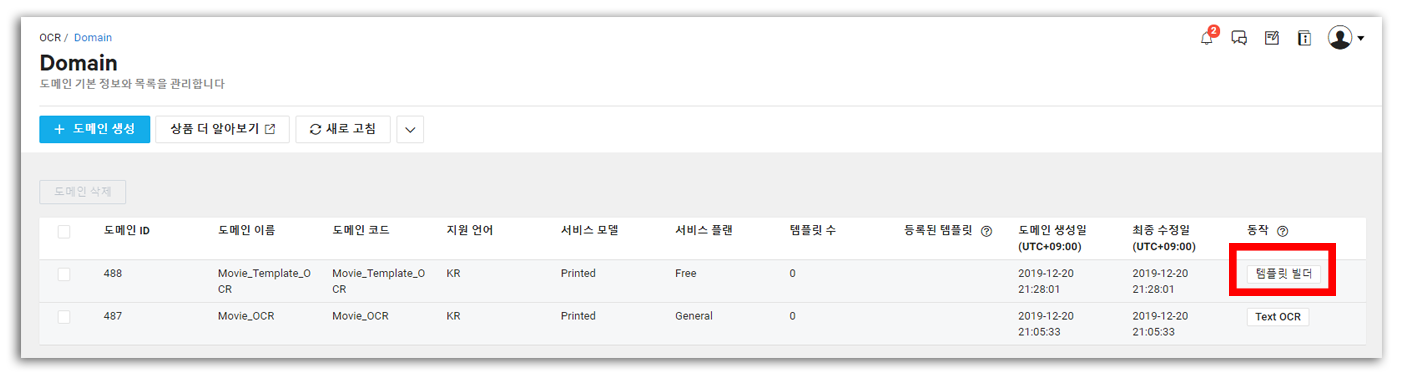
그러면 1편에서 생성한 General 도메인과 새로 만든 Template 도메인을 확인할 수 있다. [템플릿 빌더]를 눌러 템플릿 작업을 시작하도록 하자!
2. 템플릿 생성
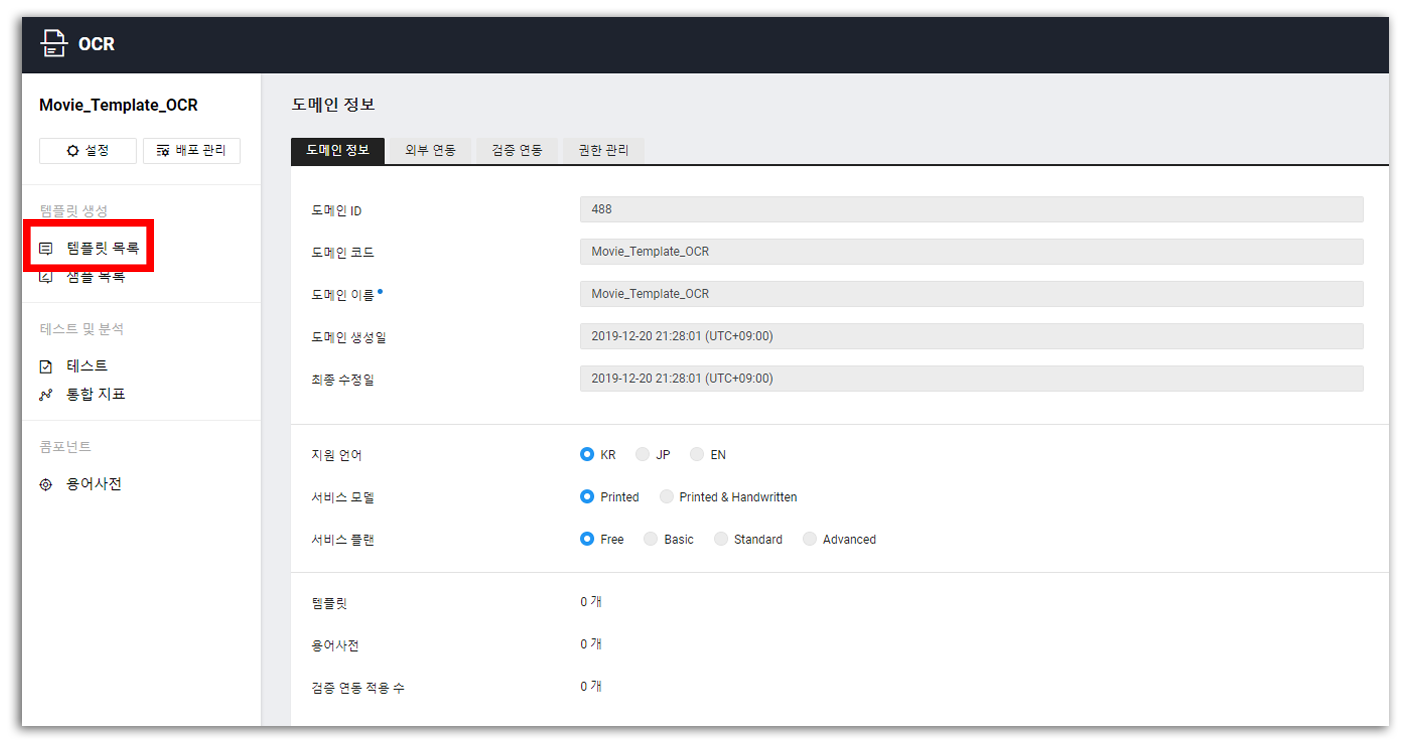 생성한 도메인을 관리할 수 있다
생성한 도메인을 관리할 수 있다
도메인을 생성했으니 커스텀을 해 줄 차례다. 좌측에 [템플릿 목록]을 눌러 템플릿을 생성하러 가보자!
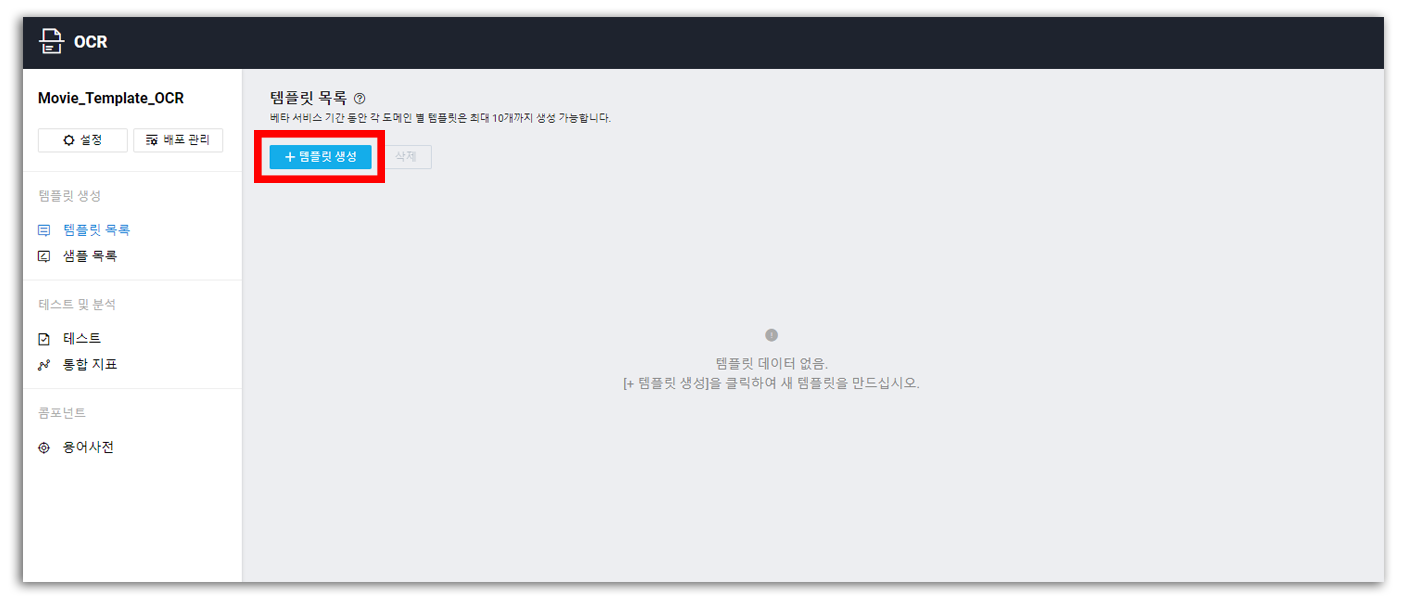 텅 빈 템플릿 리스트
텅 빈 템플릿 리스트
[템플릿 생성]을 눌러 이동하면 아래와 같은 화면을 볼 수 있다.
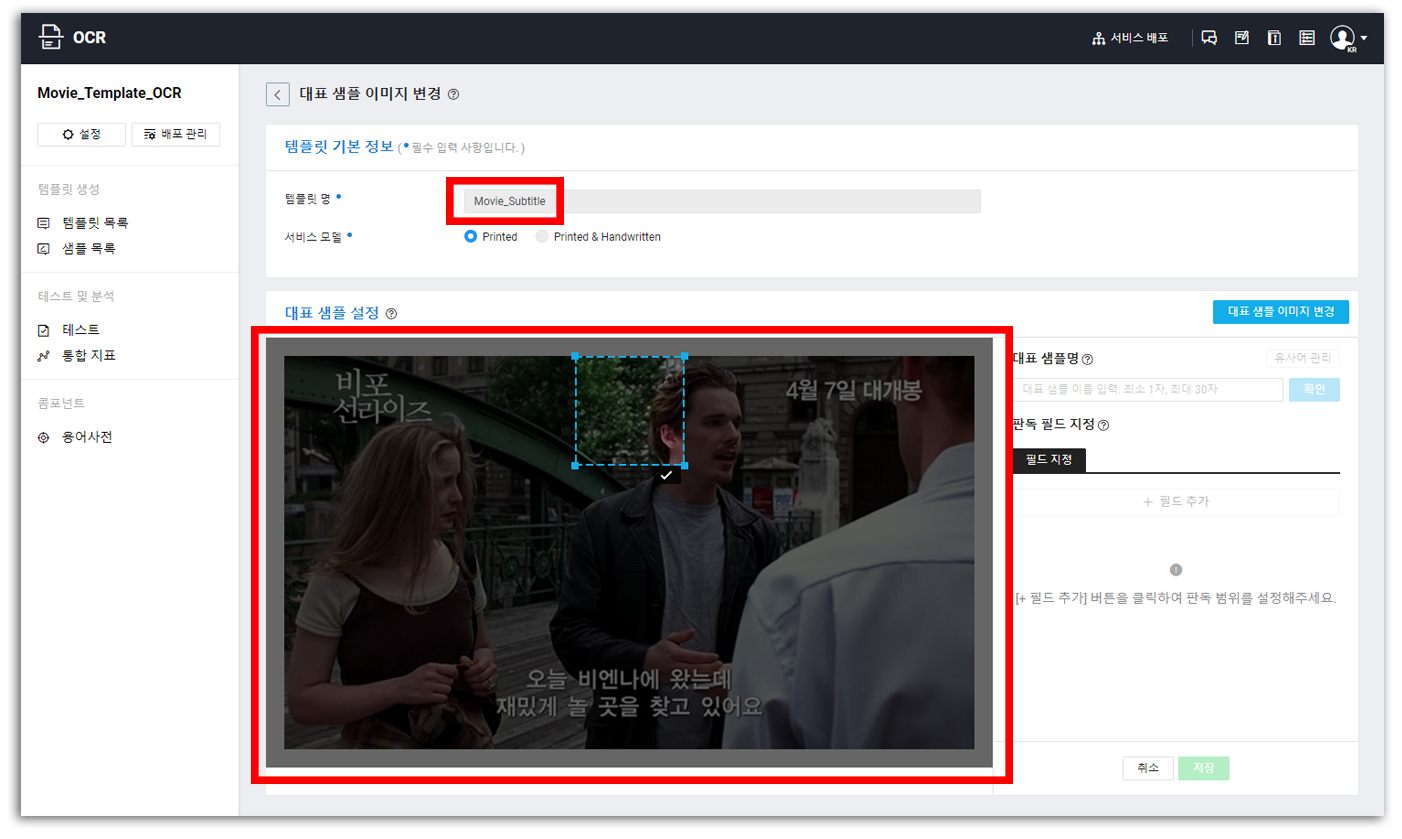
이동된 화면에서 (1)템플릿 명을 입력하고 (2)샘플 이미지를 업로드하면 위와 같은 화면을 볼 수 있다. 가장 먼저 해야 하는 것은 대표 샘플을 지정하는 것이다.
대표 샘플: API가 완성된 후, OCR 결과는
{"title": {"title name": "title result"}, "field": ["field name": "field result", ...]}와 같이 응답된다. 이 때title result를 지정해주는 과정으로 결과 분류에 사용될 수 있다.
이를테면 위의 이미지에서 좌측 상단의 비포 선라이즈 영역을 대표 샘플 영역으로 지정하면 title result가 “비포 선라이즈”가 아닐 경우 템플릿에 어긋나는 형태라고 판단하여 제외할 수 있다는 것이다. 설명한 영역을 대표 샘플 영역으로 지정하고, 영화 자막 영역을 subtitle 영역으로 지정하도록 하겠다.
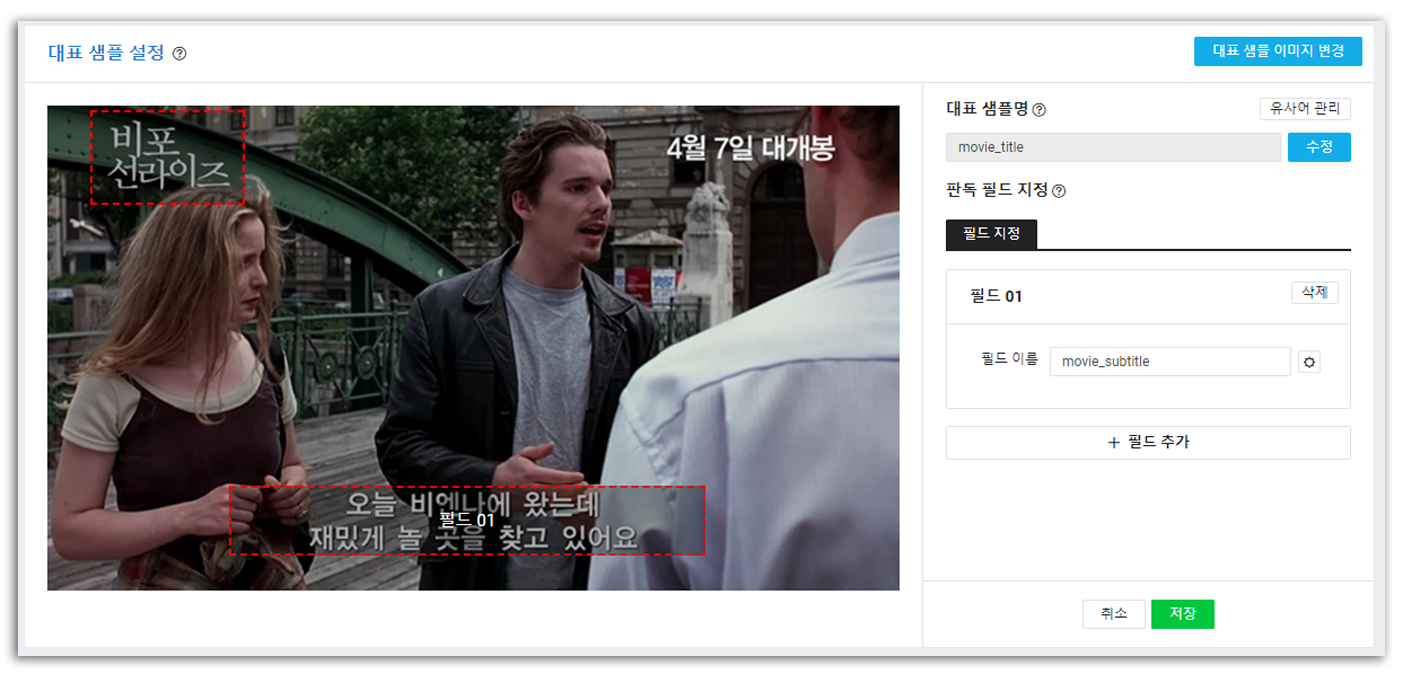 완성된 템플릿
완성된 템플릿
원하는 영역을 모두 지정한 후, [저장]을 눌러 템플릿을 저장하도록 하겠다. 여기서 지정해 준 필드 이름은 후에 결과의 각 필드별 key값으로 전달되니 헷갈리지 않도록 예쁘게 명명해주도록 하자.

저장 후, 좌측 메뉴의 [템플릿 목록]을 확인해보면 방금 만든 템플릿이 저장되어 있는 것을 볼 수 있다. 이때 템플릿 ID은 후에 사용될 수 있으므로 기억해 두도록 하자(여러 개의 템플릿을 사용하는 경우).
3. API 생성
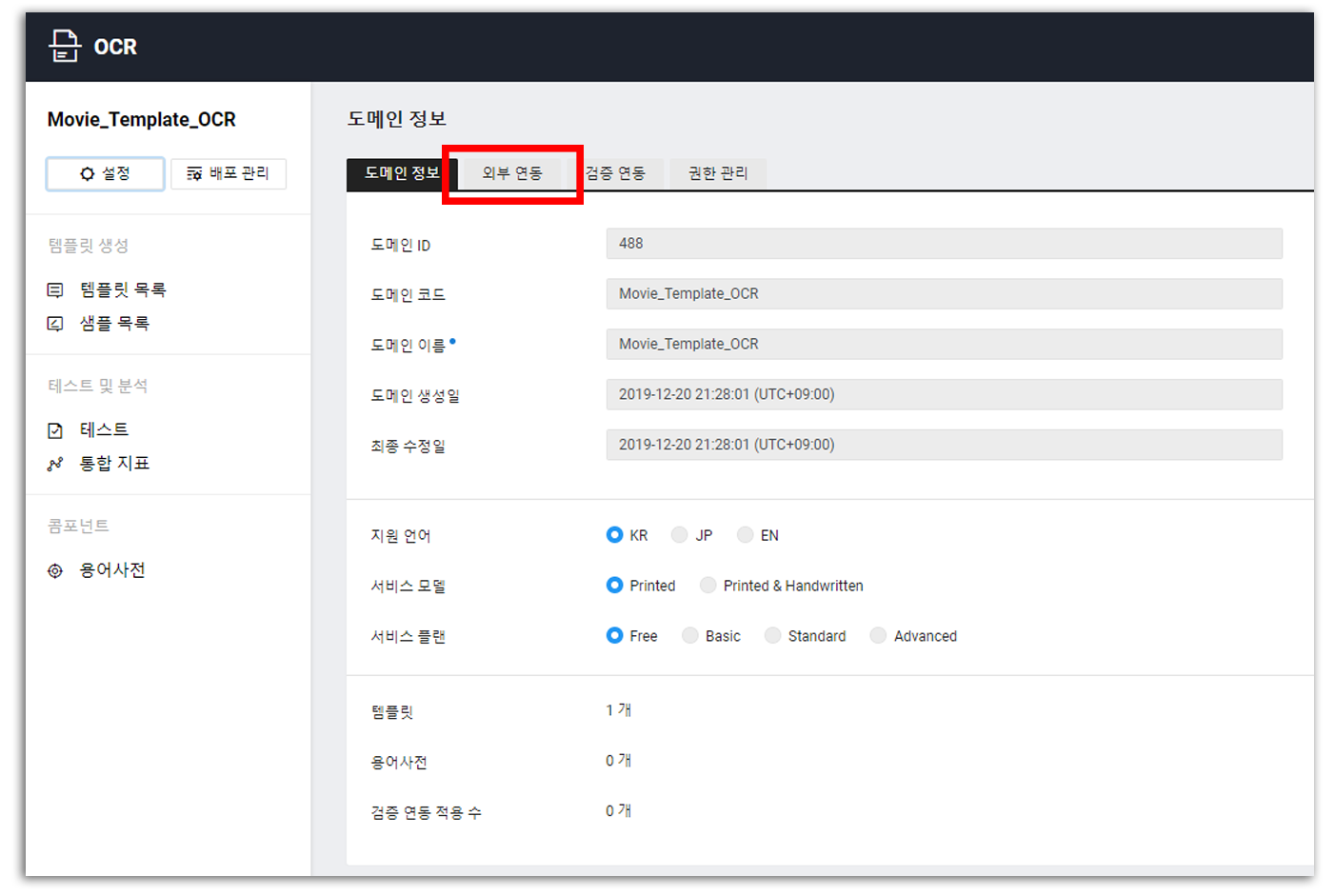
좌측 메뉴 상단부의 [설정]을 눌러 도메인 정보 페이지로 돌아온다. 그리고 [외부 연동] 탭을 클릭해 API 설정 페이지로 넘어가자!
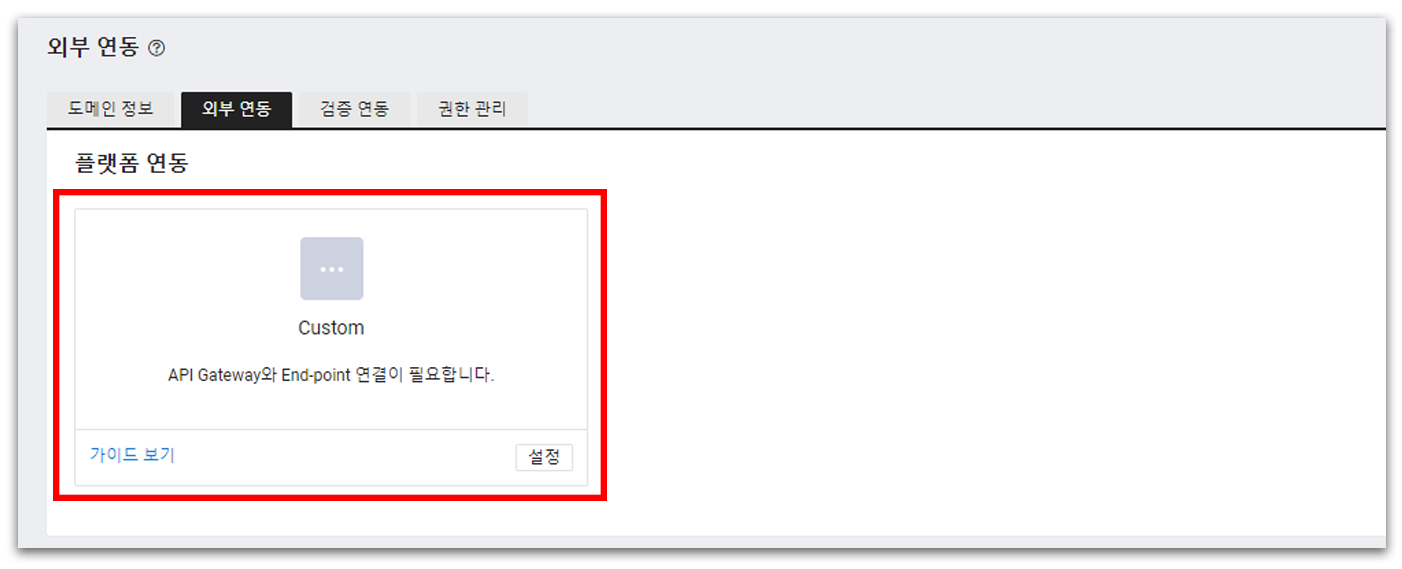
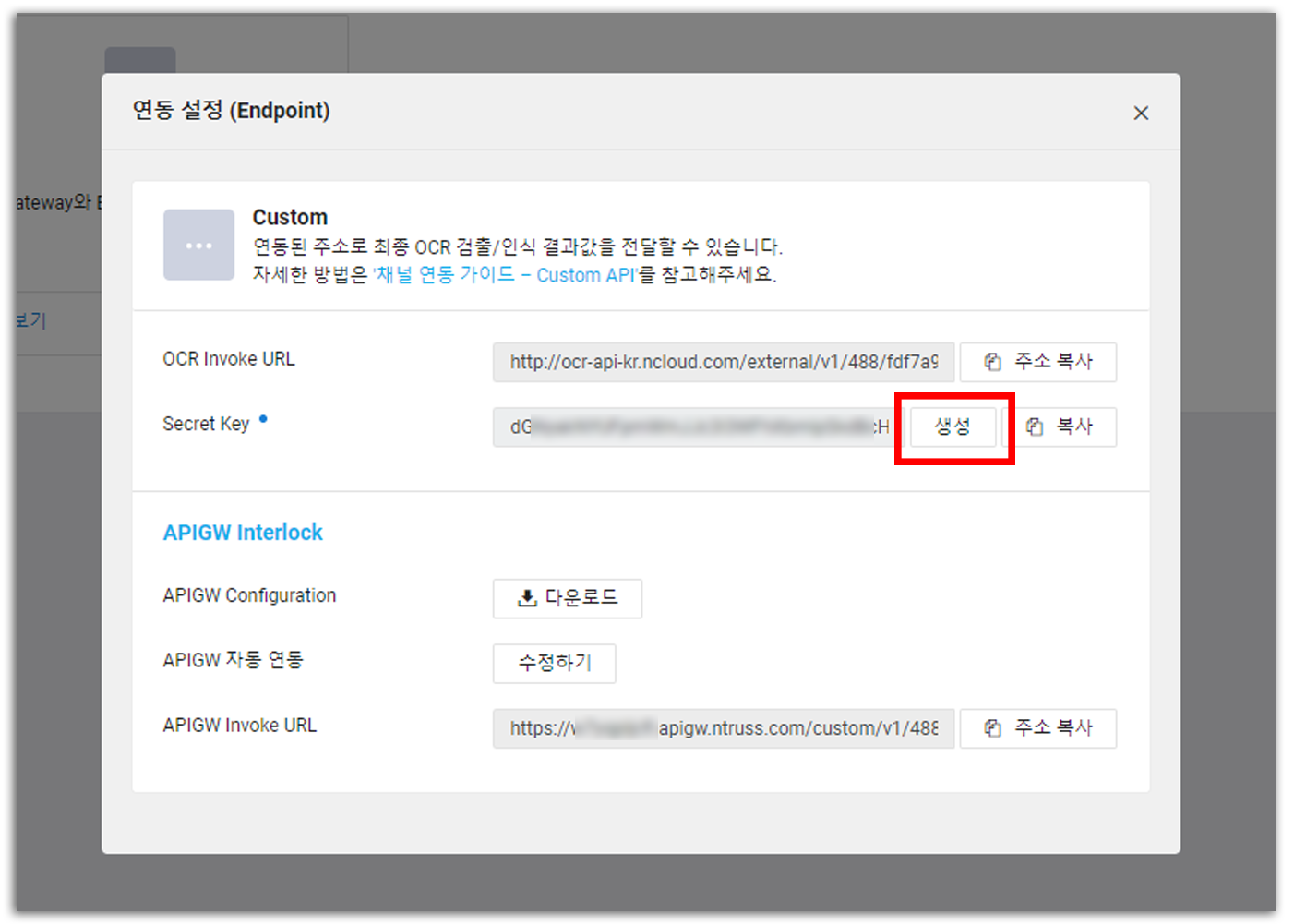
General OCR을 진행했을 때와 동일하게, Secret Key를 생성한다. APIGW Invoke URL은 1편을 진행했다면 이미 생성되어 있을 것이고, 그렇지 않았다면 [자동 연동]을 눌러 URL을 생성해준다.
4. API 배포
General OCR은 Secret Key와 APIGW Invoke URL만으로도 사용할 수 있었기에 저 페이지에서 섣불리 “다했다~” 를 해버릴지도 모른다. 하지만 생성된 URL로 보내보면 아래와 같은 에러를 마주할 것이다.
{
'code': '1021',
'message': 'Not Found Deploy Info',
'path': '/external/v1/488/abc123abc123abc123/infer', /*private uid obfuscated*/
'timestamp': 1576746215096
}
이는 API가 배포되지 않아 발생하는 에러이다. 어서 마무리 작업을 확실히 하고 마침표를 찍도록 하자.
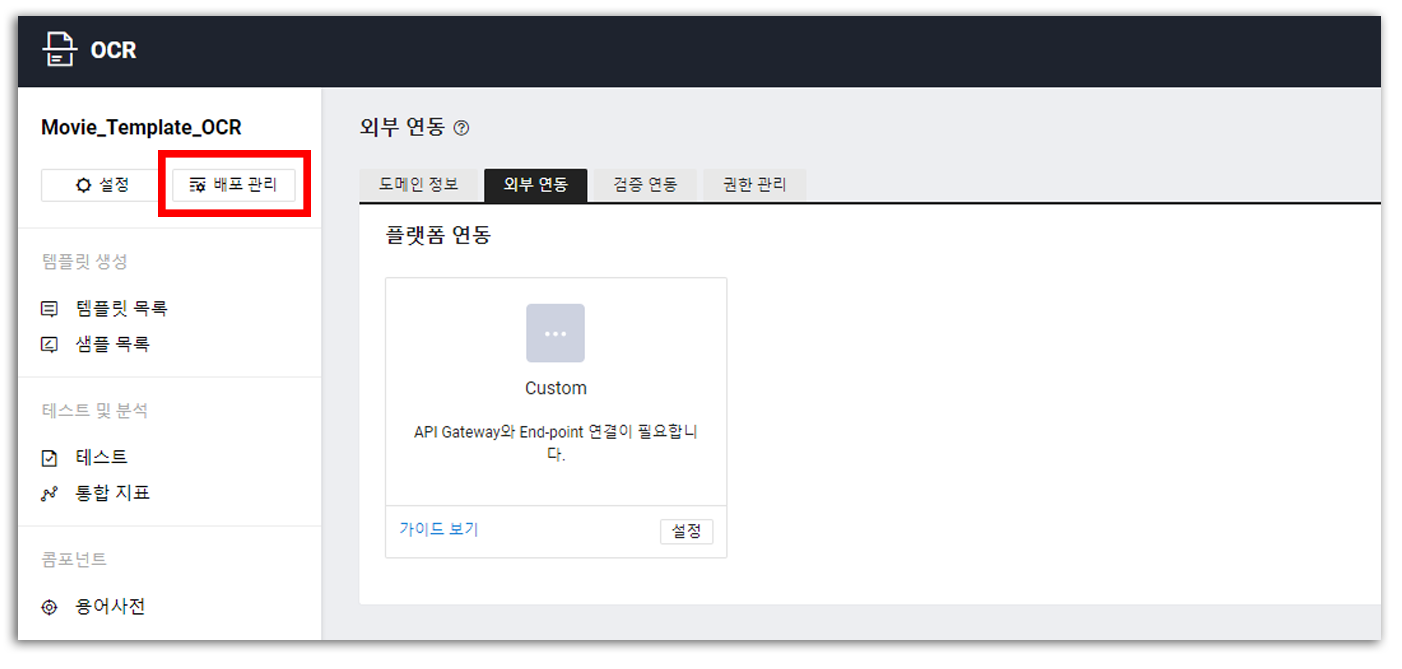
연동 설정을 마무리하고 좌측 메뉴 상단부의 [배포 관리]로 이동한다.
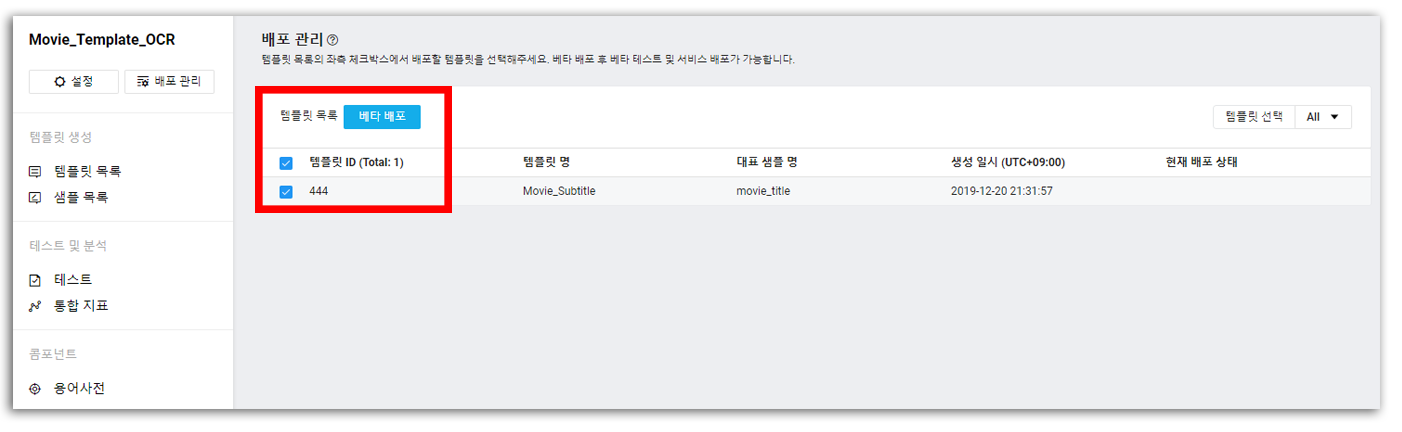
생성한 템플릿을 체크하고, [베타 배포]를 눌러 템플릿을 배포한다.
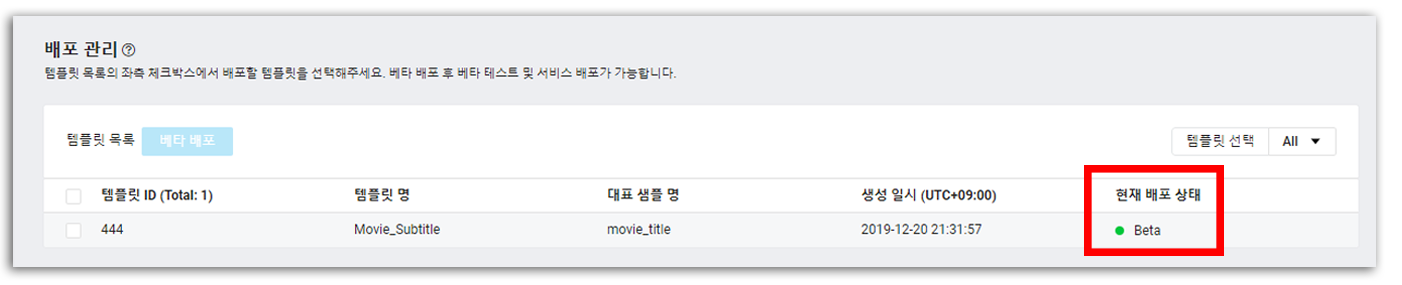
현재 배포 상태 가 Beta 상태로 변경된 것을 확인할 수 있다. 이는 테스트 단계이므로 아직 배포가 완료된 것이 아니다. 확실한 서비스를 위해 베타 테스트를 진행한 후, 배포를 완료하도록 하자.
좌측 메뉴의 [테스트]을 눌러 테스트 페이지로 이동한다.
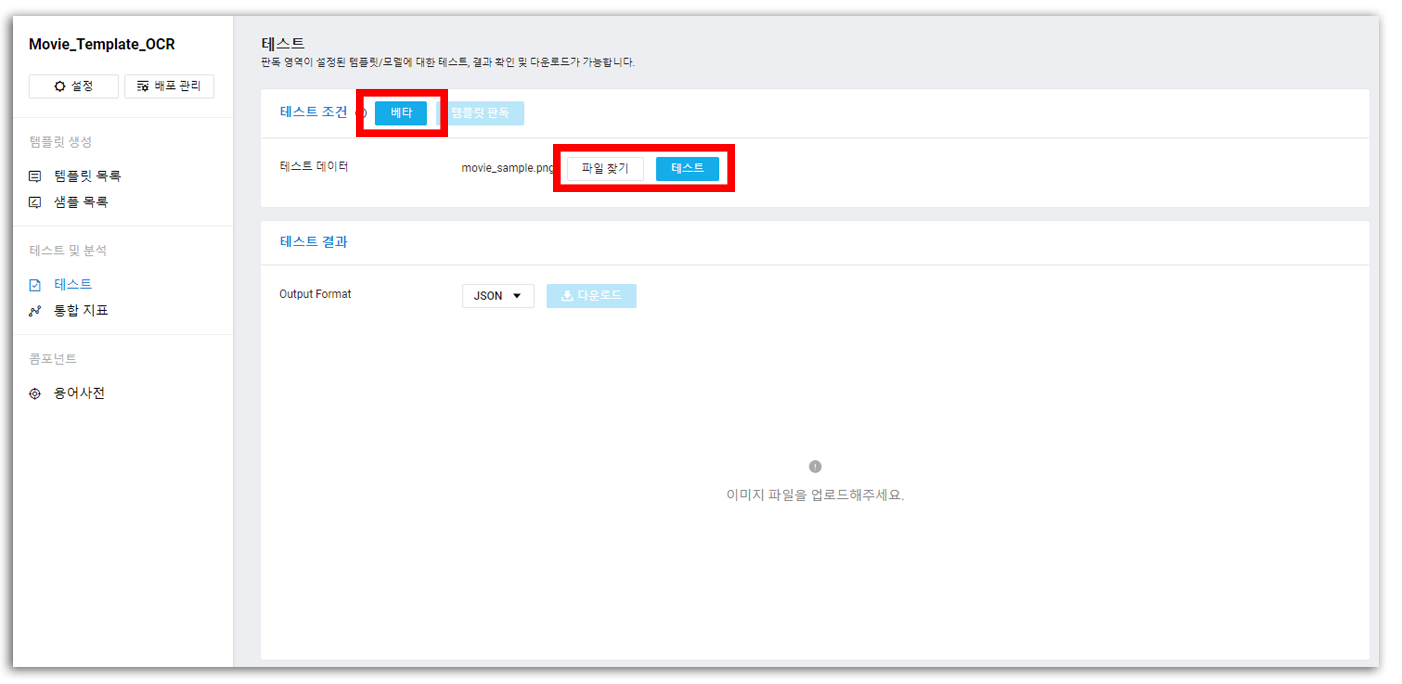
베타 테스트를 진행할 예정이므로 테스트 조건은 베타로 선택. 이미지를 업로드한 후, 테스트!
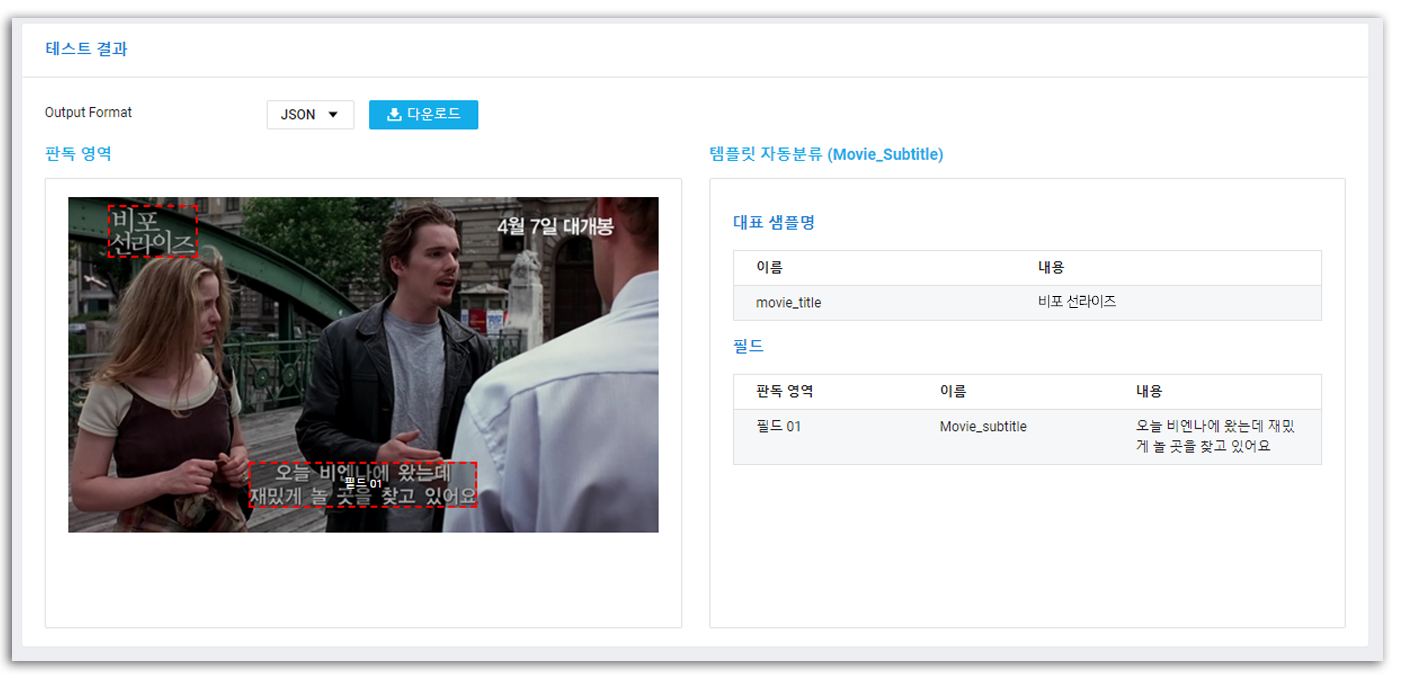 테스트 결과
테스트 결과
우리가 의도한 대로 지정한 영역에 대해서만 OCR을 진행함을 알 수 있다, 성공적이다! 어서 배포를 마치고 코드에서도 정상적으로 동작하는지 확인해보자. 페이지 최상단의 메뉴 바에서 [서비스 배포]를 눌러 최종 배포를 마무리하길 바란다.
 얼른 배포하고 코딩하러 가자..!
얼른 배포하고 코딩하러 가자..!
5. 테스트
 예시 이미지
예시 이미지
테스트 환경은 General OCR 때와 동일하다, 다만 유의점이라면 여러 개의 템플릿을 사용할 경우, "templateIds" 컬럼을 포함해 템플릿을 지정해줘야 한다는 것. 물론 컬럼을 포함하지 않을 경우 자동으로 맞는 템플릿을 찾지만 명확하게 지정하는 것을 권장한다. 1편에서 사용한 소스를 그대로 첨부하겠다.
import json
import base64
import requests
with open("./movie_sample.png", "rb") as f:
img = base64.b64encode(f.read())
# 본인의 APIGW Invoke URL로 치환
URL = "https://<your url>.apigw.ntruss.com/custom/v1/000/<your url>/general"
# 본인의 Secret Key로 치환
KEY = "<your secret key>"
headers = {
"Content-Type": "application/json",
"X-OCR-SECRET": KEY
}
data = {
"version": "V1",
"requestId": "sample_id", # 요청을 구분하기 위한 ID, 사용자가 정의
"timestamp": 0, # 현재 시간값
"images": [
{
"name": "sample_image",
"format": "png",
"data": img.decode('utf-8')
# "templateIds": [400] # 설정하지 않을 경우, 자동으로 템플릿을 찾음
}
]
}
data = json.dumps(data)
response = requests.post(URL, data=data, headers=headers)
res = json.loads(response.text)
{
'version': 'V1',
'requestId': 'sample_id',
'timestamp': 1576748247494,
'images': [{
'uid': '123456a123456b1234567', /*private uid obfuscated*/
'name': 'sample',
'inferResult': 'SUCCESS',
'message': 'SUCCESS',
'matchedTemplate': {'id': 444, 'name': 'Movie_Subtitle'},
'title': {
'name': 'movie_title',
'bounding': {
'top': 45.31195,
'left': 144.9561,
'width': 189.04782,
'height': 109.76625
},
'inferText': '비포\n선라이즈', 'inferConfidence': 0.9905509},
'fields': [{
'name': 'movie_subtitle',
'bounding': {
'top': 607.4006,
'left': 448.08237,
'width': 501.85226,
'height': 99.57385
},
'valueType': 'ALL',
'inferText': '오늘 비엔나에 왔는데\n재밌게 놀 곳을 찾고 있어요',
'inferConfidence': 0.9994903
}],
'validationResult': {'result': 'NO_REQUESTED'}
}]
}
General OCR보다 훨씬 깔끔하게 결과가 나오는 것을 알 수 있다. 정형화된 데이터를 다루는 게 목적이라면 이보다 적합한 것은 없을 정도로… 현재 Naver Cloud Platform의 OCR Service는 무료로 제공되고 있으므로, OCR이 필요하다면 활용하는 것을 적극적으로 권장한다.