이전 글
불현듯 한본어 서비스를 만들어 보고 싶다는 생각이 들었다. 인터넷 방송이나 유튜브를 즐겨보시는 분은 익숙하실 텐데 한본어가 뭐냐면…
이렇게 한국어 발음을 일본어로 적고 Text-to-Speech(TTS)를 활용해 일본어스러운(?) 한국어를 만드는 것이다.
한국어 목소리 → 일본어 STT → 텍스트 문장 → 일본어 TTS → EZ하게 한본어?!
가 기본 아이디어였다.
내가 아는 한 가장 쉽고 정확하게 STT와 TTS를 제공하는 곳은 네이버 클라우드 플랫폼(이하 NCP)이 분명하므로 이번에도 NCP를 활용해보았고, 그 과정을 정리해보고자 한다.
1. 애플리케이션 등록
우선 NCP로 이동하여 서비스를 신청하도록 하자. [서비스] → [AI Service] → [Clova Speech Recognition(CSR)]로 이동한 후 [이용 신청하기]를 눌러주길 바란다.
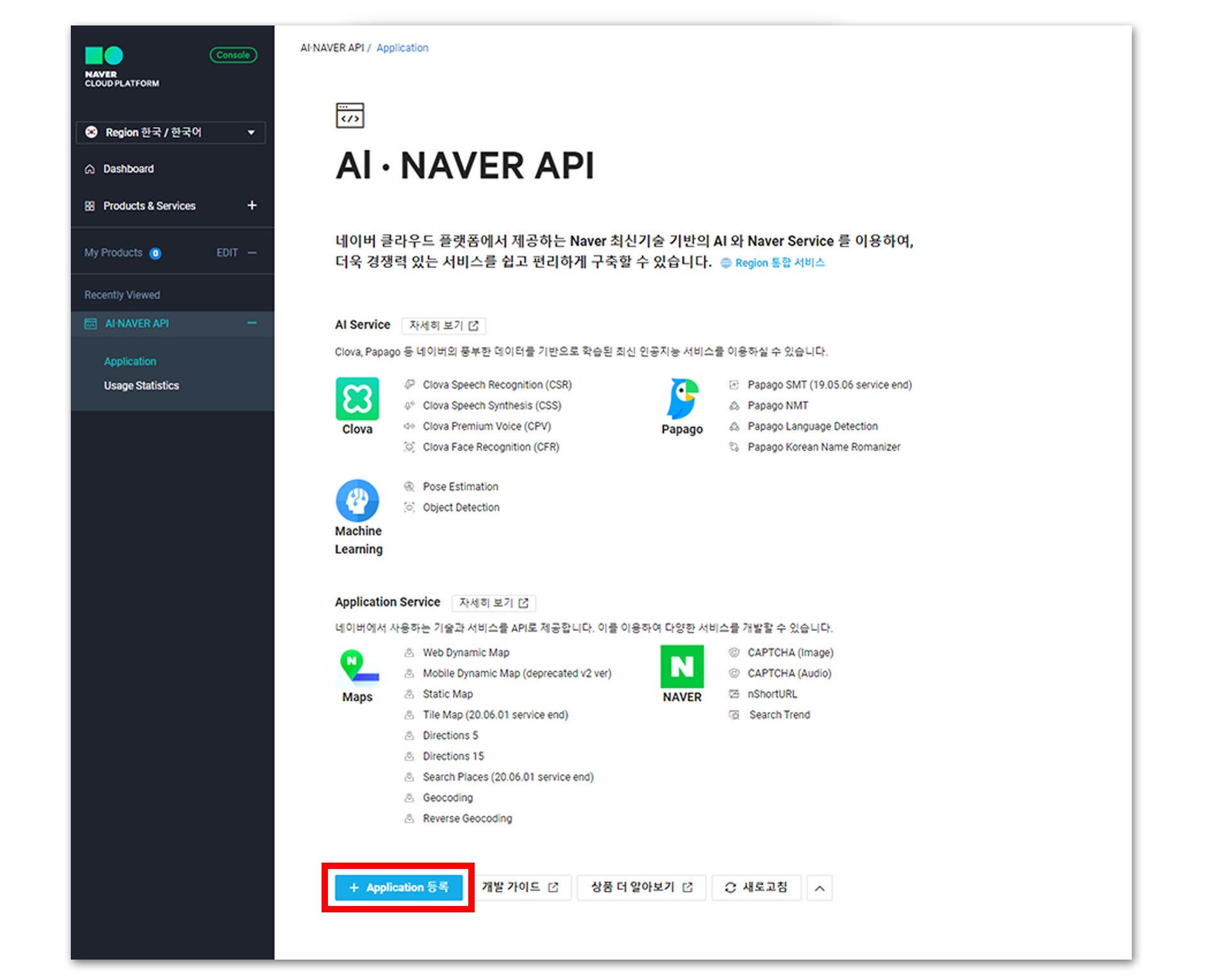
이동하고 나면 위와 같은 화면을 만나게 될 텐데, [Application 등록]을 눌러 진행한다.
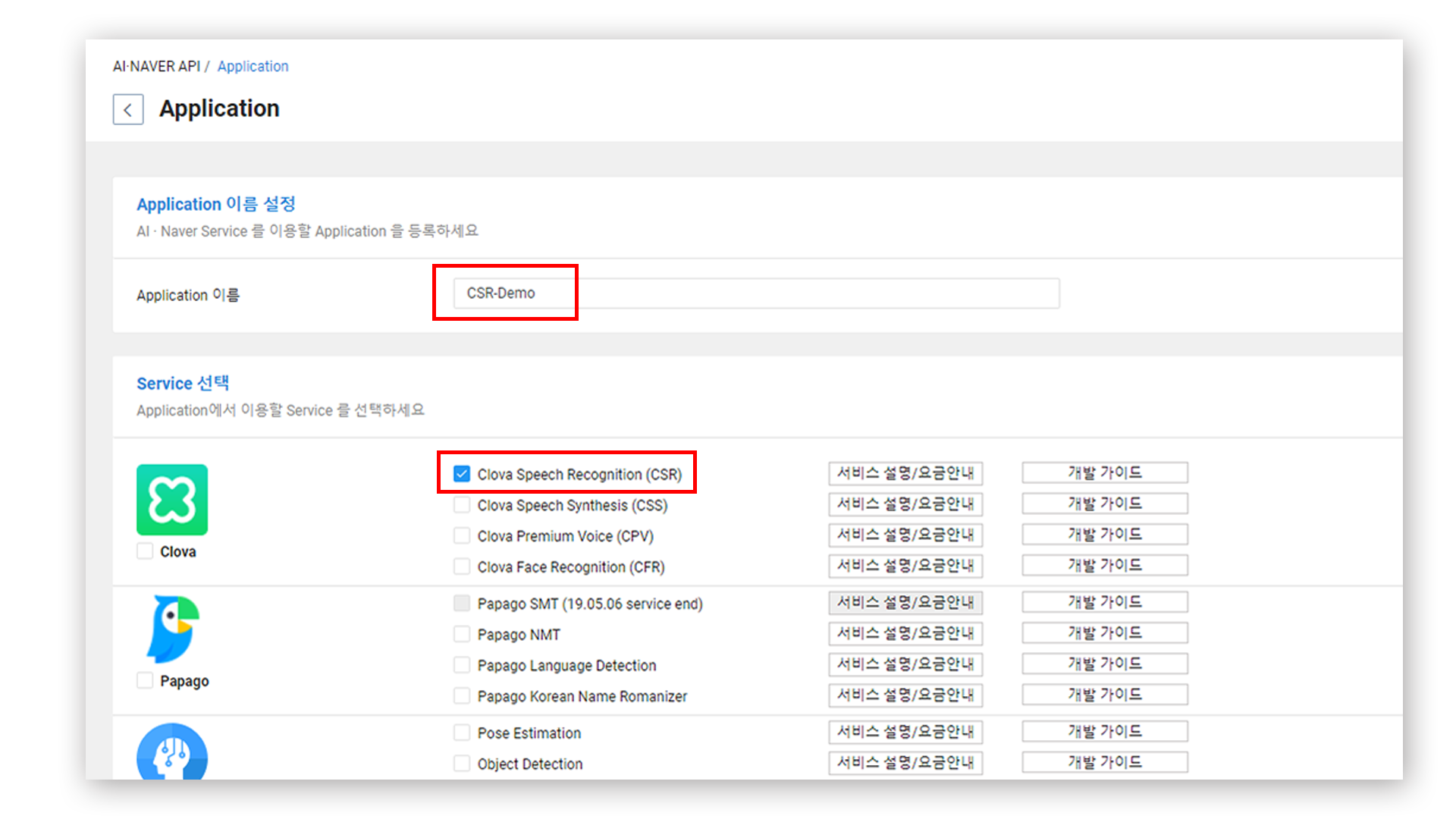
Application 이름을 입력한 후, 아래 리스트에서 원하는 서비스를 선택한다. NCP에서 제공하는 STT 모듈의 이름은 Clova Speech Recognition(CSR) 임에 유의하자. 체크!
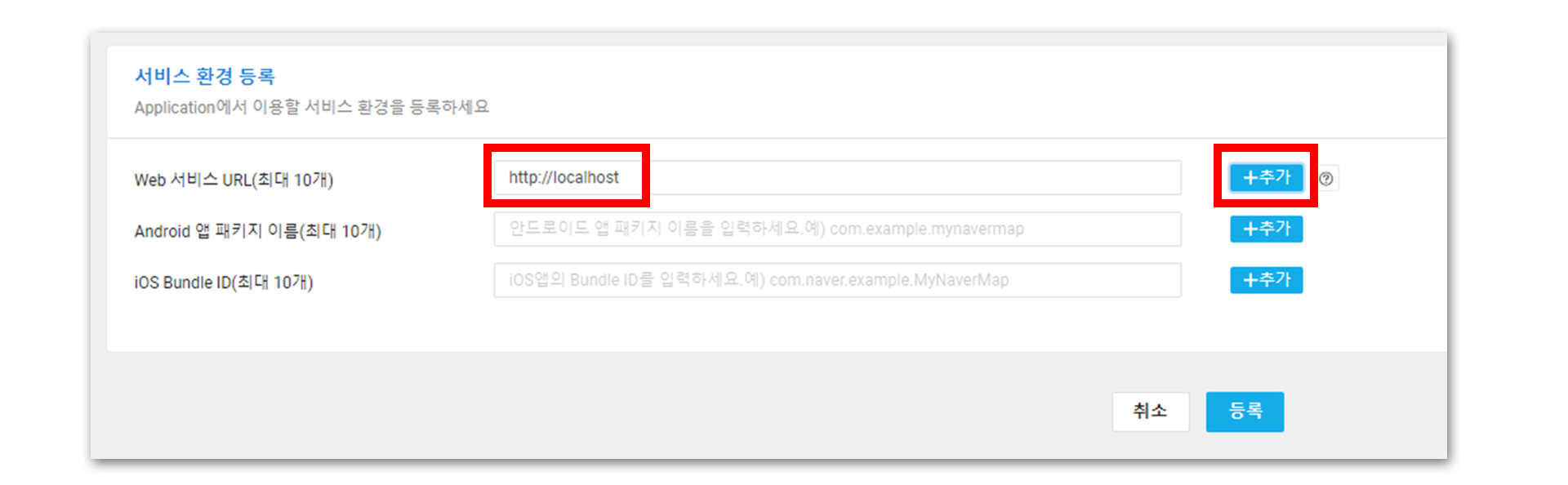
하단으로 내려오면 서비스 환경 등록 부분이 있는데, 요청을 보낼 IP를 적으면 된다. 이번 글에서는 로컬에서만 구동할 것이므로 http://localhost 라고 적은 후 URL을 추가하자. Android와 iOS, 로컬 외의 Web은 이번 글에서는 다루지 않는다.
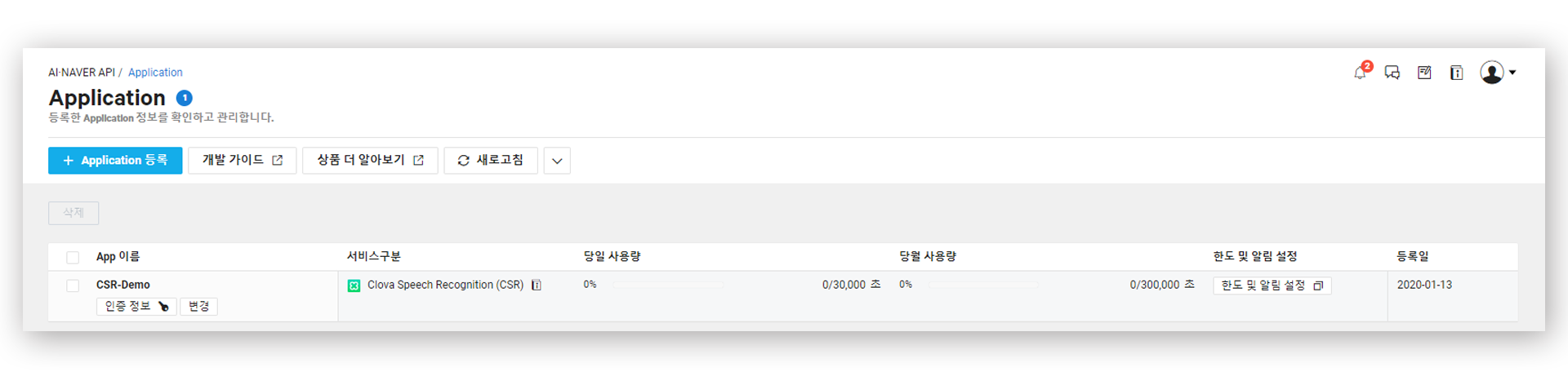
모든 과정을 마치고 나면 Application이 성공적으로 등록된 것을 확인할 수 있다.
2. API 사용
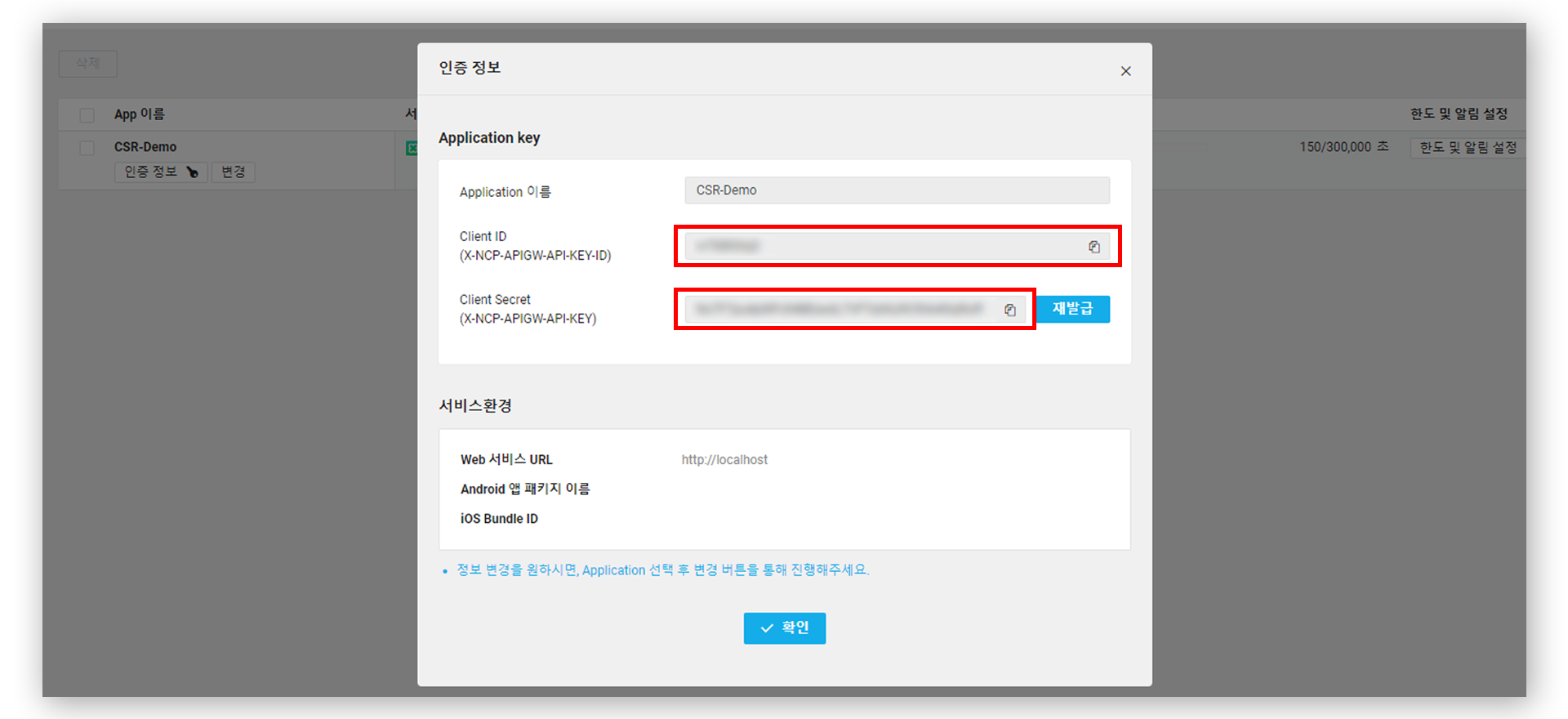
생성된 Application의 [인증 정보]를 눌러 Client ID 와 Client Secret 을 메모해둔다. 여기까지가 NCP에서 할 일! 이제 본인이 사용하는 파이썬 환경으로 이동하자.
* 참고: 필자는 Jupyter Notebook에서 테스트를 진행했는데, 본 API는 허용할 URL을 지정해주는 방식이다 보니 그 외의 파이썬 환경에서는 동작하지 않을 수 있다.
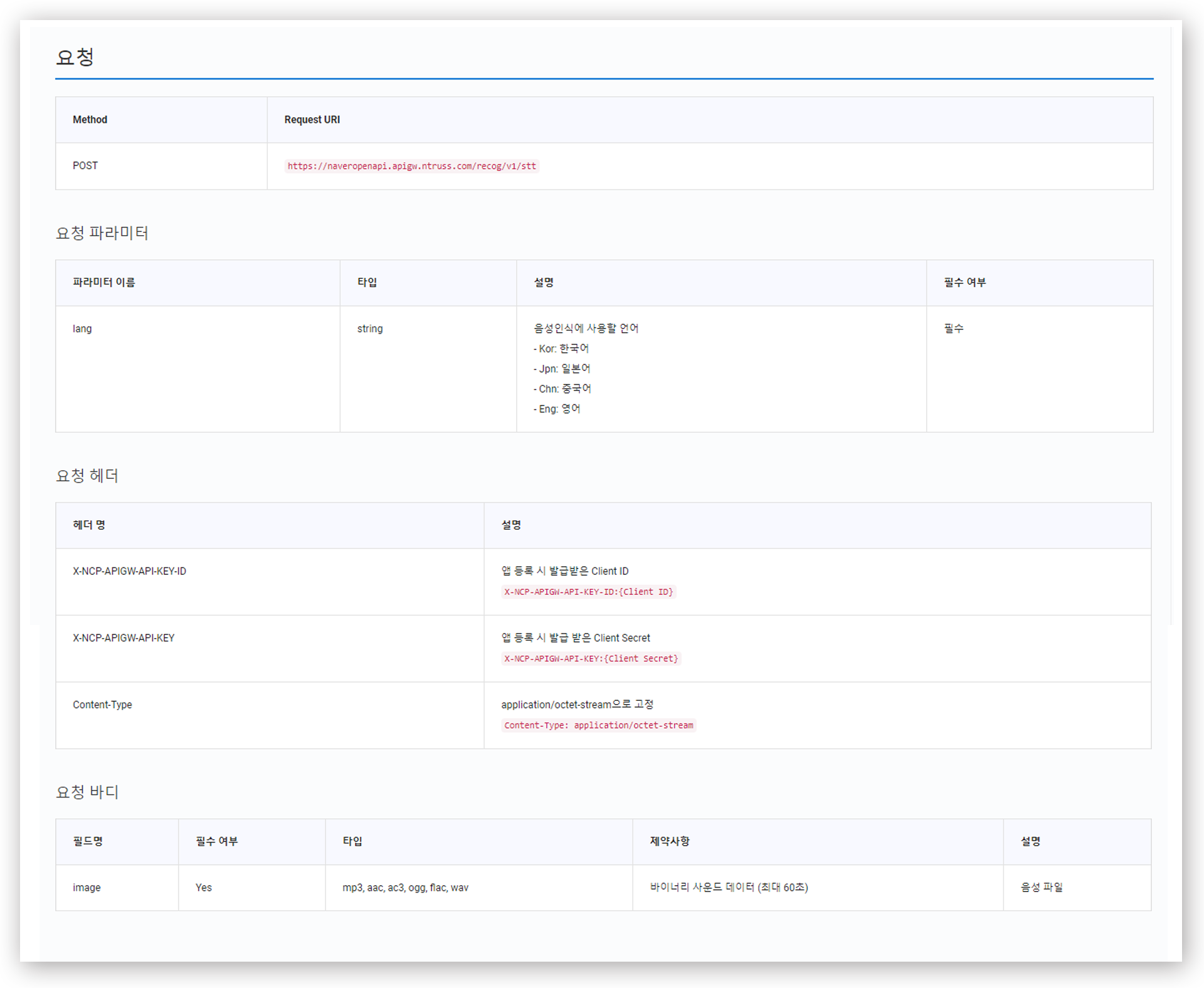
NCP에서 제공하는 API 참조서에 첨부된 요청 정보이다. 요청을 보낼 URL, 파라미터와 헤더, 바디… 정말 쓰기 쉽게 잘 작성되어 있다! 이제 테스트를 진행하기 위한 목소리를 가져와보자.
"네이버 클라우드 플랫폼의 CSR 테스트를 위한 데모 문장입니다."
실험을 진행한 소스는 다음과 같다.
import json
import requests
data = open("your/path/to/voice.mp3", "rb") # STT를 진행하고자 하는 음성 파일
Lang = "Kor" # Kor / Jpn / Chn / Eng
URL = "https://naveropenapi.apigw.ntruss.com/recog/v1/stt?lang=" + Lang
ID = "your_client_id" # 인증 정보의 Client ID
Secret = "your_secret" # 인증 정보의 Client Secret
headers = {
"Content-Type": "application/octet-stream", # Fix
"X-NCP-APIGW-API-KEY-ID": ID,
"X-NCP-APIGW-API-KEY": Secret,
}
response = requests.post(URL, data=data, headers=headers)
rescode = response.status_code
if(rescode == 200):
print (response.text)
else:
print("Error : " + response.text)
// Expected: "네이버 클라우드 플랫폼의 CSR 테스트를 위한 데모 문장입니다."
output: // Original Vesion
{"text":"네이버 클라우드 플랫폼의 csr 테스트를 위한 템 5 문장입니다"}
이 정도 정확도라면 필자가 “데모” 를 “템오” 라고 발음했다고 인정하는 게 나을 것 같다… 일전에 STT 관련 업무를 하시는 분을 뵌 적이 있었는데, “잘못된 단어는 문맥상 더 맞는 단어로 고쳐주는 것이 맞지 않느냐” 라고 여쭙자 “우린 들리는 대로 그대로 적을뿐, 그 이상은 언어 처리하는 분이 해야 한다” 라는 답변을 받은 적이 있었다. 아마 이런 케이스에서 그것이 여실히 드러나는 것 같다.
한 문장만 하면 재미없으니, 두 가지 실험을 더 해보려고 한다.
Fast Version
Tune Version
개발자로써 이게 얼마나 가혹한 테스트인지는 알고 있지만 ^*^ 그래도 혹시 놀라운 결과가 있을 지도 모르니… 소스는 동일한 소스에서 파일 경로만 변경하였다.
// Expected: "네이버 클라우드 플랫폼의 CSR 테스트를 위한 데모 문장입니다."
output: // Fast Vesion
{"text":"네이버 클라우드 플랫폼에 시작했으면 된 문장입니다"}
// Expected: "네이버 클라우드 플랫폼의 CSR 테스트를 위한 데모 문장입니다."
output: // Tune Vesion
{"text":"네이버 클라우드 플랫폼 단어 문장입니다"}
음… 적어도 출신은 확실하다. 그리고 어느 정도의 Confidence를 갖는 게 아니라면 입력하지 않는 듯하다. 그 증거로 Tune Version에 “CSR 테스트를 위한” 부분이 생략되어 있다. 그리고 이를 확인할 수 있는 테스트가 또 있는데, 필자의 원래 목적을 상기해보자!
바로 한본어 테스트인데, Tune Version을 입력으로 전달하되, Language 값을 Kor 에서 Jpn 으로 변경해보겠다!
output: // Tune Vesion to JPN
{"text":"ニダー"}
입력에 비해 아주 짧은 결과가 나왔다. 이는 확실히 알아들을 수 없는 단어는 가장 유사한 단어로 치환하지 않고, 생략해버림을 알 수 있는 대목이다. 그럼 마지막으로 Original Version에 대해 잘 동작하는지 확인해보고, 글을 마치도록 하겠다!
output: // Original Vesion to JPN
{"text":"で僕がオタクだと飯です相手するビアンテも無駄に見た"}
뭔가 기대되는 긴 문장이 등장했고… 실제 발음은 어떤지 들어보도록 하자.
음...
마지막의 “무단입니다”를 제외하곤 무슨 말인지 전혀 모르겠다 ^*^ 손쉽게 한본어 서비스를 만들고자 했던 꿈은 여기까지인 걸로!